

들어가며
안녕하세요, 게임스케일파트너실입니다. 지난 4월 10일, 미국 라스베이거스에서 열린 연례 기술 컨퍼런스 구글 클라우드 넥스트 2024(Google Cloud Next ‘24)에서 인텔리전스랩스 선행개발실에서 발표한 ‘게임 산업에서의 유해 이미지 탐지’에 대해 공유하고자 합니다.
1. Google Cloud Next ‘24에 대하여
1-1. 구글 클라우드 넥스트 ‘24는 어떤 행사인가?
2024년 4월 10일, 미국 라스베이거스 만달레이베이 컨벤션센터에서 개최된 구글 클라우드의 연례 기술 컨퍼런스인 '구글 넥스트 2024'에서 넥슨의 발표가 주목을 받았습니다. 이 행사는 다양한 기술 혁신과 새로운 클라우드 솔루션을 선보이는 자리로, 약 35,000명 이상의 전문가와 업계 리더가 참석한 가운데, 인텔리전스랩스 선행개발실 윤준호 엔지니어는 ‘게임 산업에서의 유해 이미지 탐지’를 주제로 발표를 진행하였습니다.
많은 발표 중에서 Google Cloud Next ‘24에서 Best Session 으로 선정 되기도 하였으며, 이후에 국내에서 진행된 ‘게이밍 온 구글 클라우드’ 행사에 초청 받아 후속 발표를 진행하기도 했습니다.
으로 선정 되기도 하였으며, 이후에 국내에서 진행된 ‘게이밍 온 구글 클라우드’ 행사에 초청 받아 후속 발표를 진행하기도 했습니다.
으로 선정 되기도 하였으며, 이후에 국내에서 진행된 ‘게이밍 온 구글 클라우드’ 행사에 초청 받아 후속 발표를 진행하기도 했습니다.
그림 1: 윤준호 엔지니어 구글 클라우드 넥스트 24에서 발표 (출처 : 조선비즈)
이날 한국 기업 중에서는 넥슨을 포함하여 대한항공, 카카오브레인, 카카오헬스케어, 당근마켓 등이 세션 연사로 참여하여 구글 클라우드 활용 및 협업 사례에 대한 발표를 진행하였습니다.
토마스 쿠리안, 구글 클라우드 CEO는 기조 연설을 통해 행사의 시작을 알렸고, 특히 기업의 생성형 AI 혁신을 가속화할 수 있는 ‘AI 생태계’ 비전을 강조하였으며, 그 중에서 고객 응대 및 소통, 직원 생산성, 콘텐츠 제작 영역에서의 글로벌 혁신 사례를 공유 하였습니다.

그림 2: 구글 클라우드 넥스트 24 이미지 (출처 : Madclub)
2. 구글 클라우드와의 협력 배경
2-1. AI를 활용한 유해 이미지 탐지의 중요성
게임 산업에서 유해 이미지를 탐지하는 일은 매우 중요합니다. 오늘날 게임 유저들은 단순히 플레이어로서의 역할을 넘어, 자신만의 커스텀 아이템을 제작하고 이를 소셜미디어(SNS)에 공유하는 크리에이터로서 활동하고 있습니다. 이러한 활동은 게임 환경을 더욱 풍부하게 하지만, 때로는 부적절한 콘텐츠의 공유로 이어질 수 있어 실시간 모니터링과 신속한 대응이 필수적입니다.
일반적인 AI 모델은 특정 도메인에 적용될 때 예상치 못한 어려움에 직면하는 경우가 많습니다. 특히, 게임 내에서의 애니메이션 이미지와 같이 독특한 형태의 이미지를 인식하는 것은 더욱 까다로운 일입니다.

그림 3: 게이밍 산업에서 이미지 탐지의 중요성
3. 구글 클라우드와의 협업 여정
3-1. 구글 클라우드와의 협업을 통한 돌파구
수많은 일반 API를 테스트했지만, 필요한 세 가지 조건 - 실시간으로 뛰어난 탐지 성능, 라이브 데이터셋에 대한 모델 맞춤화, 합리적인 운영 비용을 충족하는 솔루션을 찾지 못했습니다. 그래서 자체적으로 AI 모델을 개발하기 시작했지만, 이것만으로는 부족했습니다.
구글 클라우드와의 협업을 통해 저희는 이러한 문제를 해결할 수 있는 완벽한 솔루션을 찾을 수 있었습니다. 구글 클라우드는 단순한 GCP 서비스 이용을 넘어서, 저희만의 요구사항에 맞춘 맞춤형 A-Z 솔루션을 제공해 주었습니다. 이를 통해 다양한 아이디어와 모델을 통합된 환경에서 실험할 수 있었고, 실제 운영 데이터에 적용할 때 큰 성과를 거둘 수 있었습니다.
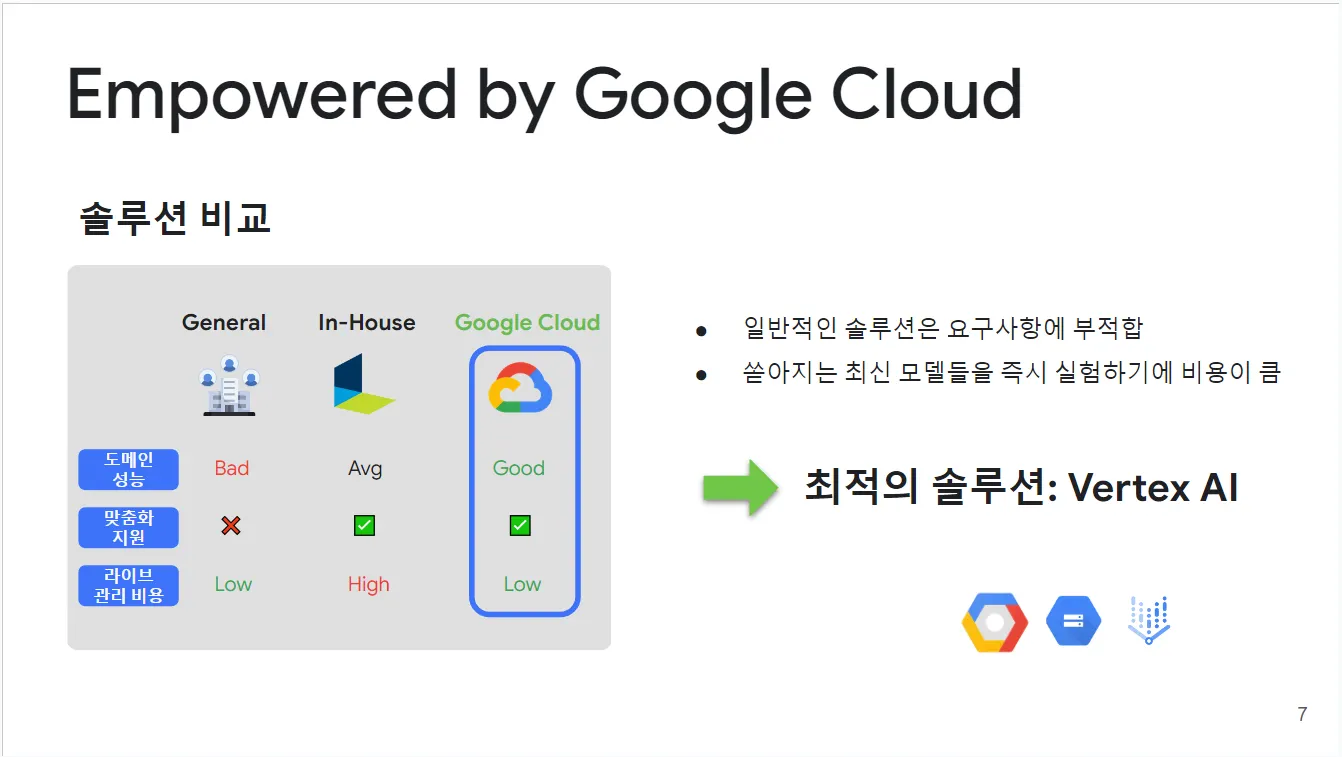
그림 4: 솔루션 비교 장표
3-2. 프로젝트 개발 과정
프로젝트는 Auto ML을 사용하여 최적의 파이프라인 구조를 설계하는 것에서 시작했습니다. 이후 데이터 세트 정의를 다듬고, 새로운 이미지 전처리 방법을 시도하는 등 첫 4주 동안 다양한 접근 방식을 모색했습니다. 그 후 더 깊은 모델 실험을 진행했으며, Gen AI를 사용한 비전 질의 응답과 임베딩 벡터 탐색 같은 비전통적인 실험도 시도했습니다.
3-3. 12주 9번의 실패와 3번의 성공
12주 동안 총 12번의 실험을 진행했으며, 이 중 9번은 실패했지만 3번의 실험에서는 큰 성공을 거두었습니다. 이 과정에서 빠른 실패를 통해 더 나은 결과를 도출할 수 있었으며, 이는 Vertex AI와 구글 클라우드 팀의 협업 덕분이었습니다.
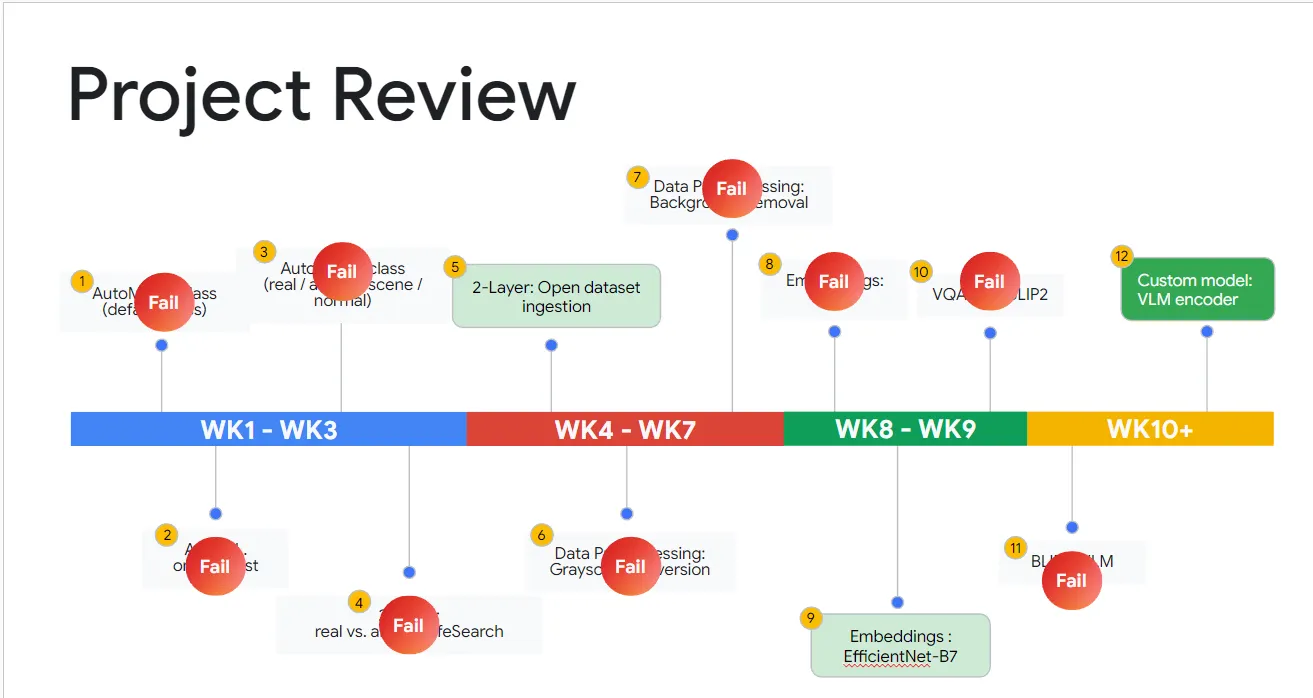
그림 5: Project Review 로드맵
3-4. 프로젝트 리뷰
1) 2-Layer : 도메인별 특화 모델 실험
이 실험은 입력 이미지를 실사, 애니메이션, 게임 이미지로 분류하는 다중 도메인 특화 모델을 사용합니다. 실사 이미지는 Google Cloud Safesearch 모델로 처리되고, 애니메이션과 게임 이미지는 도메인별 특화 모델을 거칩니다. 이 모델들은 Open dataset과 AutoML로 성능이 향상되었으나, 구조의 복잡성과 비효율성 때문에 최종적으로 사용되지 않았습니다. 그러나 게임과 애니 도메인에 대한 일부 성능 향상 기법은 채택되었습니다.
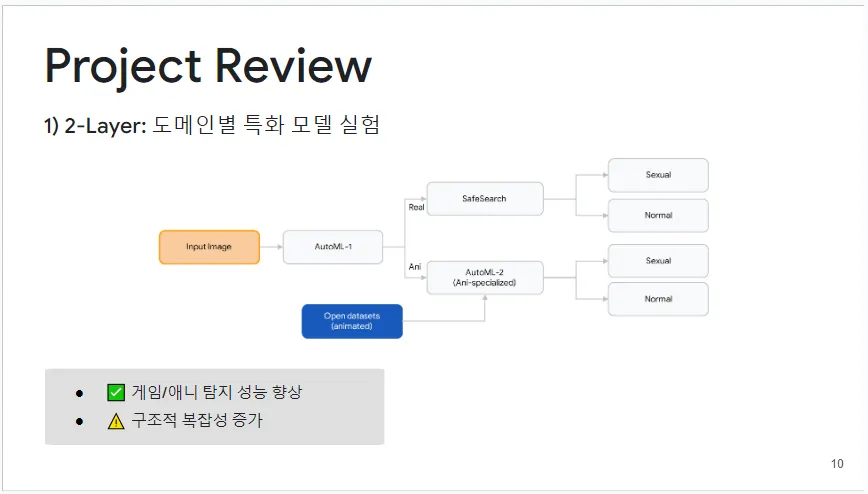
그림 6: 2-Layer : 도메인별 특화 모델 실험
2) Embedding 모델 실험
이 실험은 이미지 임베딩을 활용하여 기존 모델의 오탐지 문제를 개선하기 위해 수행되었습니다. 동일 클래스 내 높은 다양성, 특히 음란 클래스에서 분류하기 어려운 데이터의 문제를 해결하기 위해 이미지 모델의 임베딩 부분을 벡터 인코더로 사용하고 이미지 벡터 검색으로 방향을 전환했습니다. 이 접근법은 직접적인 분류에는 성공적이지 않았지만, 이상 탐지와 라벨 교정에 효과적이어서 잘못 라벨링된 데이터를 정정하는 데 큰 성과를 거두었습니다. 또한, 다양한 모델의 이미지 임베딩을 테스트하며 잘 학습된 임베딩의 활용성을 확인했고, 이는 최종 모델 설계에 중요한 인사이트를 제공했습니다.
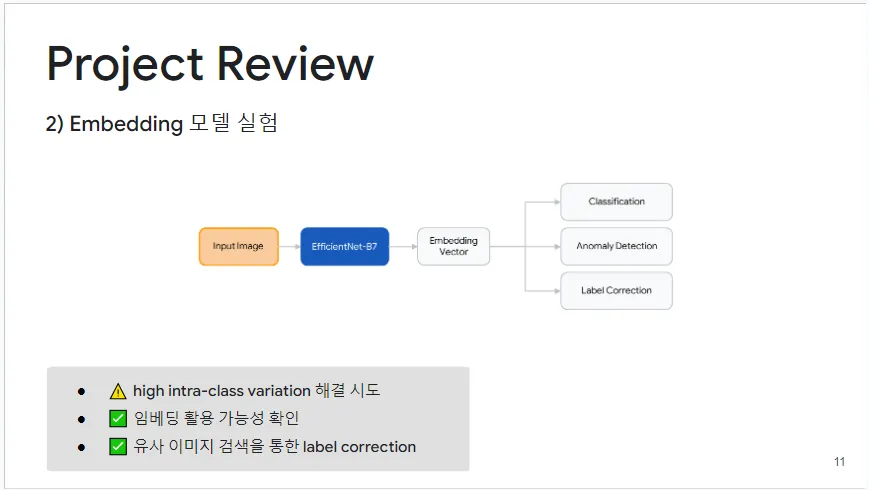
그림 7: Embedding 모델 실험
3) Vision Question Answering 실험
이 실험은 거대 생성 AI를 활용한 Vision Question Answering (VQA) 접근법을 통해 진행되었습니다. 입력 이미지를 인코더를 통과시킨 후, 자연어 질문과 함께 모델에 입력하여 결과를 도출하는 방식입니다. 이 방법을 통해 기존에 해결하기 어려웠던 복잡한 경우(hard case)의 탐지에 성공했고, Vision Language Model의 가능성을 확인할 수 있었습니다. 그러나 이 구조를 전면적으로 채택하기에는 일반화 성능이 미흡하고 연산 비용이 높다는 문제가 있었습니다.
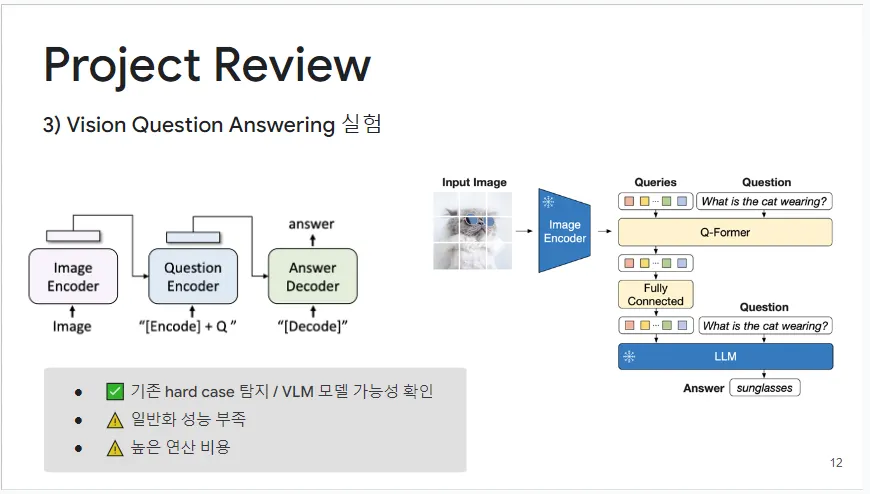
그림 8: Vision Question Answering 실험
4) Custom VLM encoder
마지막 주요 성과 실험은 이전 실험들에서 확인된 가능성을 토대로 최적의 구조를 개발하여 라이브 서비스에 반영한 메이저 업데이트입니다. 이 구조는 오픈 데이터셋을 활용한 도메인 일반화, 이미지 임베딩을 통한 성능 극대화, 그리고 대규모 데이터로 사전 학습된 비전 언어 모델의 이미지 인코더 사용 등 세 가지 요소를 통합했습니다. 이 커스텀 모델은 파인 튜닝을 거쳐, 실사 도메인과 게임 및 애니메이션 도메인에서 모두 높은 성능을 발휘하는 이미지 탐지 모델로 구축되었습니다.
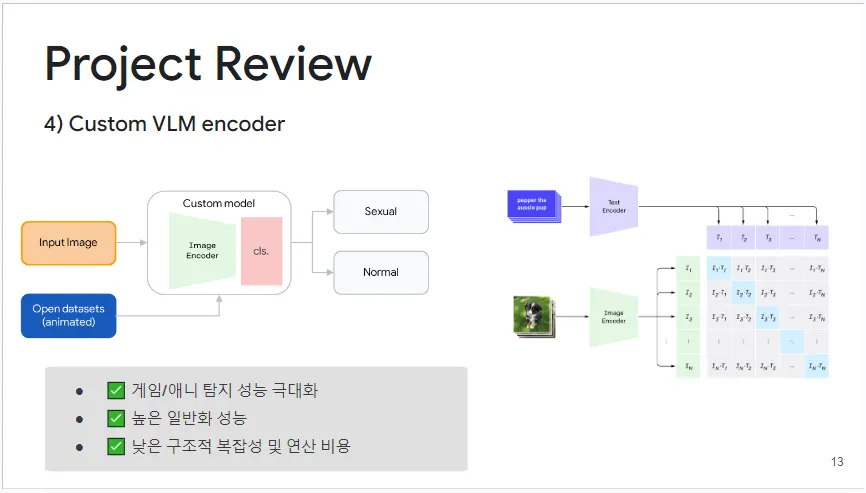
그림 9: Custom VLM encoder
3-5. 결과 : 운영 비용 81% 감소, 응답 시간 73.8% 단축
이 협업 덕분에 모델은 이전 모델들이 감지하지 못했던 어려운 사례를 성공적으로 감지하며 성능이 4.2% 향상되었습니다. 또한, 실시간 서버에 통합되어 운영 비용은 81% 감소했으며, 응답 시간은 73.8% 단축되었습니다. 이제 우리는 매우 효과적인 반자동 시스템을 운영 중입니다.

그림 10: Business Impact 장표
나가며
이 성공적인 프로젝트를 바탕으로, 우리는 다른 게임 회사들에게도 우리의 모델을 서비스로 제공하는 가능성에 대해 논의를 시작할 예정입니다. 구글 클라우드와의 이번 협업을 통해 얻은 경험과 기술은 다른 조직들에게도 큰 도움이 될 수 있을 것입니다. 또한, 우리는 계속해서 새로운 AI 모델을 실험하며, 특히 Vertex AI와 Gen AI를 활용한 신흥 기술을 탐색할 것입니다.
앞으로 더 많은 관심과 성원 부탁드리겠습니다
Reference
 함께 읽으면 좋은 콘텐츠
함께 읽으면 좋은 콘텐츠 









 테크블로그 문의 gs_site_contents@nexon.co.kr
테크블로그 문의 gs_site_contents@nexon.co.kr