

Table of contents
들어가며
.jpg&blockId=67c7d1ed-a1f0-4837-8fcd-84fc0bcc1835)
추천을 받는다는 것이 이제는 일상이 된 것 같습니다. 주변을 둘러보면 생각보다 다양한 분야에서 추천이 제공되고 있는데, 이는 게임에서도 마찬가지입니다. 게임은 유저마다 취향과 플레이 방식이 다양하기 때문에 개인의 선호에 맞게 콘텐츠를 개인화하는 것은 효과가 높은 분야입니다.
인텔리전스랩스에서도 유저분들이 넥슨 게임을 재밌게 즐길 수 있도록 여러 가지 추천을 적용하고 있습니다. 그중 게임 상점에서 유저분들의 취향에 맞는 아이템 추천 로직을 개발해 본 경험을 공유드리고자 합니다. 
1. 게임에서의 추천 서비스
개인의 작은 데이터로 취향을 예측할 수 있는 추천 알고리즘
추천을 위한 방법론들을 살펴보면 Content Based Filtering (CBF), Collaborative Filtering (CF), Matrix Factorization (MF), Item2Vec, Deep Learning을 결합한 접근 방식까지 다양한 알고리즘들이 있습니다. 이들 대부분은 유저, 아이템, 그리고 구매 여부(또는 평점) 데이터를 활용하여 추천합니다.
인텔리전스랩스에서는 유저의 취향을 알기 위해 더욱 다양한 게임 정보를 활용하고 있습니다. 우리가 누군가에게 추천을 해줄 때 그 사람의 취향에 대해서 더 물어보거나 추천해 줄 아이템의 여러 특징을 고려해서 추천하는 것처럼 더 효과적인 추천을 지향합니다.
예를 들면 게임 유저 및 아이템의 메타 정보를 고려하여 아이템을 추천할 수 있습니다. 메타 정보는 특정 아이템이 있다면 그 아이템의 색상, 장착 부위, 가격 등 특정 아이템에 대해 설명해 주는 데이터를 의미합니다. 그런데, 이런 메타 정보들을 추가할수록 데이터의 자료형 (정수, 실수 등)이 다양해지고 메타 정보에 해당하는 경우보다 해당하지 않는 경우가 더 많아집니다. 즉, 유저가 구매한 아이템에 대해서만 정보를 가지고 있기 때문에 가지고 있지 않은 아이템에 대한 정보를 0으로 표현하면, 희소 데이터(sparse data)가 된다는 문제가 있습니다. 희소 데이터란 대부분의 값이 0인 데이터를 의미하는데요, 이러한 희소한 데이터들은 학습에 악영향을 주어 정확한 추천이 어렵습니다.
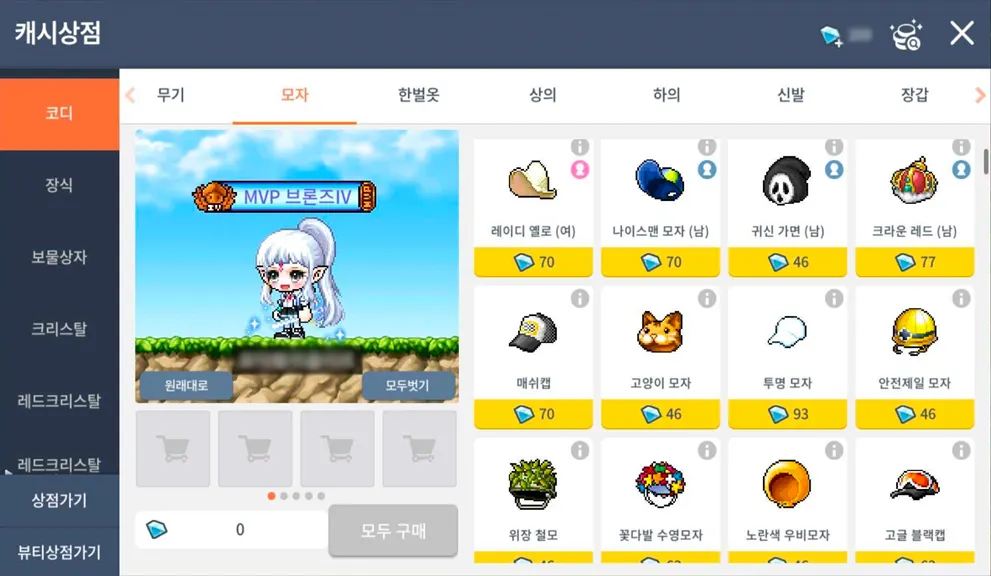
그림 1 : 게임 내의 캐시상점 화면
이런 희소한 데이터로 유저의 선호를 예측할 수 있는 알고리즘이 많겠지만 오늘은 Factorization Machine(이하 FM) 모델을 소개 드리고자 합니다. FM은 Support Vector Machine(이하 SVM)과 Factorization model의 장점을 결합한 모델입니다. SVM처럼 실수형의 피쳐 벡터를 입력(Input)할 수 있으며, 행렬 인수분해(factorizing)를 이용해서 희소한 데이터 간에도 상호작용을 모델링 할 수 있습니다. 따라서, 희소 데이터의 문제를 해결하면서도 유저나 아이템 이외의 정보들을 활용하여 추천할 수 있습니다.
더 자세히 알고 싶으신가요? 이제부터 FM이 무엇인지 살펴보고, FM 모델링으로 게임 내 치장성 아이템 추천을 어떻게 구현했는지 보면서 FM에 대해 더 자세히 알아가 보도록 하겠습니다.
2. FM의 컨셉 이해하기
모든 피처(feature)간의 관계를 모델링하는 것이 핵심!
앞서 FM은 모든 상호작용을 모델화 할 수 있다고 말씀드렸는데요. FM의 개념을 통해 좀 더 상세히 살펴보겠습니다.
degree 인 FM 모델 방정식은 다음과 같습니다. d=2라는 것은 2개 피처 사이의 관계를 고려한다는 것을 의미합니다.
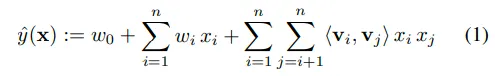
이 식에서 추정되어야 하는 파라미터들은 다음과 같습니다.
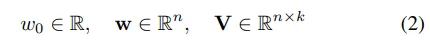
우선, (1)번 식의 첫 번째 항 은 global bias입니다. 두 번째 항을 보시면 는 i번째 개별 피처에 대한 가중치이며, 는 하나의 피처 벡터를 의미합니다. 모델링을 통해 개별 피처의 영향력(w)을 추정한다고 볼 수 있는데요. 개별 피처에 대한 가중치를 곱해서 더하면 예측값이 나오는 선형적인 형태입니다. 여기까지만 보면 간단한 식이죠. 하지만, 피처들끼리에 대한 상호작용을 고려할 수 없다는 단점이 있습니다. 그래서 두 피쳐간 상호작용을 고려한 세 번째 항이 등장하였습니다. 세 번째 항의 는 i번째와 j번째 피처 간의 상호작용 즉, 두 피처 간의 상호작용을 의미합니다. 중요한 것은 를 사용하는 것이 아니라 이를 k차원으로 인수분해된 두 벡터의 내적 로 표현했다는 것입니다. 이것은 변수간 상호작용의 잠재 벡터(latent vector)입니다.
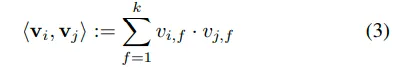
(3)번의 식을 보시면, 는 V 내부의 행을 의미하고 k개의 factor를 가진 i번째 변수이며, k는 factorization의 차원입니다. 이는 잠재 벡터 조합을 모두 고려한다는 것을 의미합니다. 따라서, d=2인 FM 모델은 각 피쳐의 1차 상관관계뿐만 아니라 한 쌍의 피처 조합의 2차 상관관계도 모두 고려하는 모델이며, 이 덕분에 희소한 데이터에서도 상호작용을 추정할 수 있습니다.
희소한 데이터에서의 상호작용
희소한 데이터 즉, 유저가 특정 영화를 보지 않았을 때 데이터에서는 보지 않았다는 의미로 0으로 표기가 될 텐데요, 영화는 매우 많고 그 영화들을 다 보기 힘들기 때문에 0이 아주 많은 데이터일 것입니다. 이런 상황에서도 어떻게 유저가 아직 보지 않은 영화에 대한 평점을 예측할 수 있는지 FM 모델에 대한 논문(Steffen Rendle, Factorization Machines, 2010)에서 발췌한 예제를 통해서 좀 더 살펴보겠습니다.
아래는 영화 평점 시스템 데이터에서 생성된 피쳐 벡터입니다.
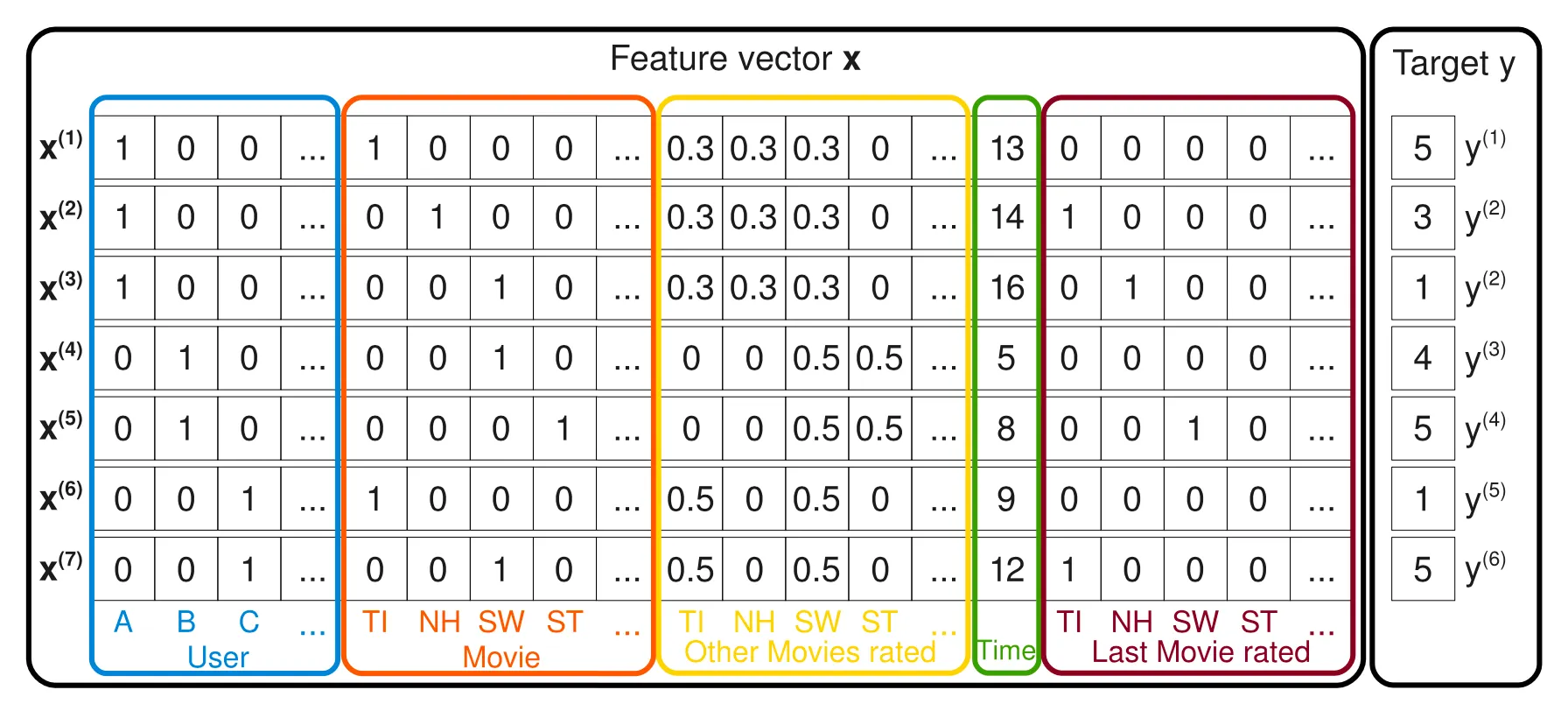
그림 2 : 영화 평점 시스템 데이터에서 생성된 피쳐 벡터 [2]
이 데이터를 통해 유저의 영화에 대한 평점을 예측할 수 있습니다. 한 행에는 하나의 유저, 하나의 아이템이 들어가는 것을 확인할 수 있고 모든 영화에 대한 평점 행렬(Matrix)은 행의 합이 1이 되도록 정규화(Normalized) 되었습니다.
위의 그림에서 파란색 영역은 유저(User)를 의미하는 변수이고, 주황색 영역은 아이템(item) 즉, 영화를 나타내는 변수입니다. 노란색 영역은 유저가 다른 영화들에 평점을 매긴 변수이며, 녹색은 월 단위 시간을 나타냅니다. 마지막 붉은색 영역은 해당 영화를 평가하기 바로 직전에 평가한 영화를 의미합니다. 그리고 맨 오른쪽 열이 목푯값(y)입니다.
예를 들어, 평점(y)을 예측하기 위해 Alice(User A)와 Star Trek(Movie ST) 사이의 상호작용을 추정한다고 가정하겠습니다. Alice는 Star Trek을 보지 않았기 때문에 데이터가 없어서 직접 추정 시 상호 작용은 0이 됩니다. 그러나, 인수분해 된 상호작용 파라미터인 를 통해 상호작용을 측정할 수 있습니다. 우선, Bob(User B)과 Charlie(User C)는 유사한 팩터 벡터(factor vector) , 를 가질 것입니다. 왜냐하면 두 유저 모두 Star Wars(Movie SW)와 관련하여 유사한 상호작용 즉, 각각 평점 4점, 5점을 주었기 때문입니다. 이것은 와 가 유사하다는 뜻입니다. 그리고 Alice는 Charlie와 다른 팩터 벡터를 가질 것입니다. 왜냐하면 Alice는 Titanic(Movie TI)에 5점, Charlie는 1점을 주었기 때문입니다. 그리고 Bob이 Star Treck과 Star Wars에 유사한 높은 점수(각 4점, 5점)를 주었기 때문에 두 영화의 팩터 벡터는 유사한 상호작용을 가질 것입니다. 결론적으로, Alice는 Star Trek에 대해 평점을 낮게 줄 가능성이 있으며, 이를 통해 Alice와 Star Trek에 대한 팩터 벡터의 내적이 Alice와 Star Wars의 팩터 벡터의 내적값과 매우 유사하다는 점을 추측할 수 있습니다.
3. FM을 활용한 치장성 아이템 추천
*추천 알고리즘 연구를 위해 예시 데이터로 모델링을 진행하였습니다.
메이플스토리M 유저분들에게 치장성 아이템을 추천하는 예제로 Python에서 xLearn이라는 라이브러리를 통해 FM 모델을 구현하는 방법을 살펴보겠습니다. xLearn 라이브러리는 Python을 통해 쉽게 구현할 수 있고 접근성이 가장 좋아서 선택했습니다.
데이터 세트
치장성 아이템 구매 데이터를 활용하여 데이터 세트를 다음과 같이 만들었습니다. 유저ID와 아이템ID 외에 구매 유저의 캐릭터 성별과 치장성 아이템의 부위 정보 및 색깔 정보 메타 데이터를 추가하였습니다. 구매한 데이터뿐만 아니라 당연히 구매하지 않은 데이터도 포함해 주어야 합니다. 왜냐하면, 구매하지 않은 아이템에 대해 구매할 확률을 추정해야하기 때문이죠!
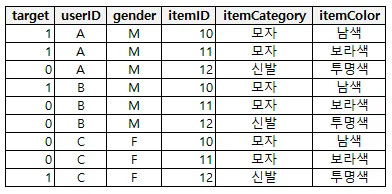
그림 3 : 데이터 세트
•
target : 구매 여부(목푯값)
•
userID : 유저ID
•
gender : 유저의 인게임 캐릭터 성별
•
itemID : 아이템ID
•
itemCategory : 아이템의 장착 부위 카테고리(모자, 신발, 상의, 하의 등)
•
itemColor : 아이템의 색상 정보
위 데이터를 train과 test 데이터 세트로 분리해 줍니다. 동일한 유저ID가 train 과 test 데이터 세트 둘 모두에 포함되지 않도록 주의가 필요합니다.
앞서 구매한 데이터뿐만 아니라 모든 아이템에 대해 구매하지 않은 데이터도 포함해 주어야 한다고 말씀드렸는데요. 그렇게 되면 비구매 데이터가 매우 많아지게 됩니다. 실제 train 데이터 세트에서도 구매 데이터가 전체 데이터 세트의 0.4% 비구매 데이터가 99.6%로 비구매 데이터가 대부분이었습니다. 극단적인 불균형 현상으로 예측값을 모두 0으로 판단할 수 있어서 다운 샘플링을 통해 데이터가 많은 쪽(비구매)을 더 적게 추출하였습니다.
해당 데이터 세트에 모든 피처가 범주형(category)이기 때문에 컴퓨터가 읽을 수 있도록 one-hot encoding을 해줍니다.
import pandas as pd
# Read csv data set
r_train = pd.read_csv("train.csv")
r_test = pd.read_csv("test.csv")
# Performs a one-hot encoding
train_onehot = pd.get_dummies(r_train,columns=['gender','userId','itemID','itemCategory','itemColor'])
test_onehot = pd.get_dummies(r_test,columns=['gender','userId','itemID','itemCategory','itemColor'])
Python
복사
one-hot encoding을 하면 데이터는 아래와 같은 형태가 됩니다.

그림 4 : one-hot enconding 결과
xLearn 라이브러리에서 FM 모델링을 할 때 csv 형식의 데이터도 수행할 수 있지만, csv 파일을 다음과 같은 libsvm 포맷의 데이터로 변환하여 사용할 수 있습니다.
<label> <index1>:<value1> <index2>:<value2> ...
•
<label>은 target을 의미합니다.
•
<index>는 피처입니다.
•
<value>는 해당 피처의 값을 의미합니다.
비구매 데이터도 포함하고 있어서 데이터 세트가 크고 매우 희소한 형태이기에 저장 공간을 낭비하게 됩니다. 따라서, libsvm 포맷의 데이터로 변환하여 사용하였습니다. 값이 0인 인덱스(index)는 제외하고 값이 있는 인덱스만 저장하기 때문에 정보를 단순하게 하고 공간을 절약할 수 있습니다.
결과적으로 아래와 같이 libsvm 형식의 데이터로 변환됩니다. csv 파일을 libsvm 형식의 데이터로 변환하는 코드는 쉽게 찾으실 수 있습니다.
0 3:1 332:1 711:1 731:1 732:1
0 3:1 464:1 713:1 729:1 732:1
0 3:1 668:1 716:1 720:1 732:1
0 3:1 691:1 717:1 723:1 732:1
0 3:1 224:1 711:1 731:1 732:1
.
.
.
Python
복사
모델링
예제 데이터를 이용해서 xLearn에 적용해 보겠습니다. 먼저, xLearn 라이브러리를 로딩합니다.
import xlearn as xl
Python
복사
다음 구문을 통해 train과 test 데이터 세트를 세팅합니다. 데이터 파일은 csv 파일과 libsvm 형식의 데이터 파일 모두 가능합니다. 단, 첫번째 컬럼에 반드시 목푯값이 있어야 합니다.
# Training task
fm_model = xl.create_fm() # Use field-aware factorization machine (fm)
fm_model.setTrain("train.txt") # Set the path of training dataset
fm_model.setValidate("test.txt") # Set the path of validation dataset
Python
복사
파라미터를 설정해 줍니다.
# Parameters:
# 0. task: binary classification
# 1. learning rate: 0.2
# 2. regular lambda: 0.002
# 3. evaluation metric: accuracy
param = {'task':'binary', 'lr':0.2, 'lambda':0.002, 'metric':'f1'}
Python
복사
•
‘task’는 구매(1), 비구매(0)의 분류 문제를 해결할 것이기 때문에 ‘binary’로 설정합니다.
•
‘lr’은 learning rate 즉, 미분 기울기의 이동 스텝을 의미하는데, 0.2가 기본으로 설정되어 있습니다. 이는 하이퍼 파라미터(hyperparameter)로, 실험을 통해서 적절한 값을 찾아 나갈 수 있는데, 이번 내용에서는 다루지 않습니다.
•
‘lambda’는 0.002가 기본으로 설정되어 있습니다.
•
‘metric’의 경우 모델 성능 평가 지표를 의미합니다. 분류 문제에서는 정확도(Accuracy)는 ‘acc’로, 정밀도(Precision)는 ‘prec’, 재현율(Recall)은 ‘recall’, F1 스코어는 ‘f1’, AUC(Area Under Curve)의 경우 ‘auc’를 입력하여 모델 성능을 확인할 수 있습니다.
모델 성능 평가 지표로는 유저가 구매한 아이템을 모델이 구매할 것이라고 예측하는지(재현율), 모델이 구매할 것이라고 예측한 것을 유저가 구매하였는지(정밀도)를 바탕으로 F1 스코어를 이용해서 모델의 성능을 평가해 보았습니다. F1 스코어란 정밀도와 재현율의 조화 평균으로, 정밀도와 재현율의 차이가 작을수록 높은 값을 가집니다. 데이터 세트의 특징상 분류 클래스 간 케이스 수의 불균형이 심하기 때문에 정밀도와 재현율을 모두 고려한 모델 성능 지표로서 판단하기 적합합니다.
설정한 파라미터와 학습 데이터를 가지고 모델을 학습시킵니다.
# Start to train
# The trained model will be stored in model.out
fm_model.fit(param, './model.out')
Python
복사
결과
위 모델이 예측한 결과로 어떻게 추천이 되었는지 샘플로 확인해 보았습니다. 캐릭터 성별이 여성인 A 유저는 ‘악마의 탄생’이라는 모자류 아이템과 ‘투명 장갑’을 구매한 경험이 있는 유저입니다. 이 유저가 구매할 가능성이 높은 아이템 순서대로 정렬하였습니다. 추천되는 아이템을 보면 투명 신발, 투명 모자, 투명 망토와 같은 투명 아이템류를 추천해 주고 있으며, 메타 데이터를 반영한 효과로 여성 캐릭터들에서 구매율이 높은 ‘네온사인 아믈릿’, ‘하트 타투 글로브’, ‘하트 리본 글러브’가 추천되는 것까지 확인할 수 있습니다.

그림 5 : 추천 모델 결과
(*해당 자료는 추천 알고리즘 연구를 위한 자료이며, 실제 메이플스토리M에 적용된 모델이 아님)
나가며
FM 모델의 간단한 개념을 살펴보고 직접 구현까지 해보았는데요. 예제 데이터로 진행한 모델링이라 성능이 좋지 않았던 점이 아쉬웠습니다. 왜냐하면, 실제 추천 결과에서 대중적으로 인기 있는 투명 모자나 투명 장갑과 같은 투명 아이템들을 추천해 주는 경우가 많았기 때문입니다.
다양한 자료형의 피처를 사용할 수 있는 자유도가 높은 모델이다 보니 향후 유의미한 피처들을 추가하고, 데이터 세트를 늘리고, 하이퍼 파라미터 튜닝을 통해 모델을 고도화시키면 다양한 아이템을 추천할 수 있을 것이라 기대합니다.
FM에서 더 발전한 FFM, AFM, PNN 이나 FM에 딥러닝을 결합한 DeepFM등 FM을 기반으로 한 많은 발전된 알고리즘도 있으니 비교해서 모델링을 진행해 보는 것도 좋을 것 같습니다. 다음에는 더 재밌고 유익한 내용으로 찾아뵙겠습니다. 읽어주셔서 감사합니다.
Reference







 테크블로그 문의 gs_site_contents@nexon.co.kr
테크블로그 문의 gs_site_contents@nexon.co.kr