

들어가며
안녕하세요. 인텔리전스랩스 통합인터페이스실의 데이터게이트웨이팀 홍길석입니다.
현재 NXCommand 서비스에서는 대량의 트래픽으로부터 업스트림 호스트를 보호하기 위한 능동형 트래픽 제어 시스템인 ATCS 기능을 제공합니다. 이러한 ATCS는 트래픽을 제어하는 다양한 과정에서 인메모리 캐시 스토리지인 Redis를 활용하고 있습니다.
이벤트 스트리밍을 위한 자료 구조인 Redis Streams는 다양한 분야에서 활용 가능한 플랫폼을 제공하는데요. 하지만 Redis Cluster 환경에서는 특정 샤드에만 트래픽이 집중되어 불균등한 부하가 발생한다는 한계점을 지니고 있었습니다.
데이터게이트웨이팀은 이러한 Redis Streams의 한계를 극복하기 위해 Redis SPAR (Stream Partition Automatic Rebalancer)이라는 라이브러리를 자체 개발했습니다. 이번 콘텐츠에서는 Redis SPAR이 Redis Streams의 한계를 어떻게 극복했는지, 그리고 Redis SPAR이 제공하는 스트림 파티셔닝 (Stream Partitioning) 기능과 파티션 리밸런싱 (Partition Rebalancing) 기능에 대해 알아보겠습니다.
1. Redis Cluster
1-1. Shard 및 Node 유형
Redis Cluster는 여러 Redis 노드로 구성된 분산 데이터베이스 시스템입니다. Redis Cluster는 데이터 분산 및 확장성을 위해 데이터를 논리적으로 그룹화한 단위인 샤드 (shard)로 이루어져 있습니다. 샤드는 하나 이상의 노드로 구성되며, 노드는 다시 한 대의 프라이머리 노드 (primary node)와 여러 대의 레플리카 노드 (replica node)로 구분할 수 있습니다.
그림 1은 Redis Cluster의 기본적인 구조를 나타냅니다.
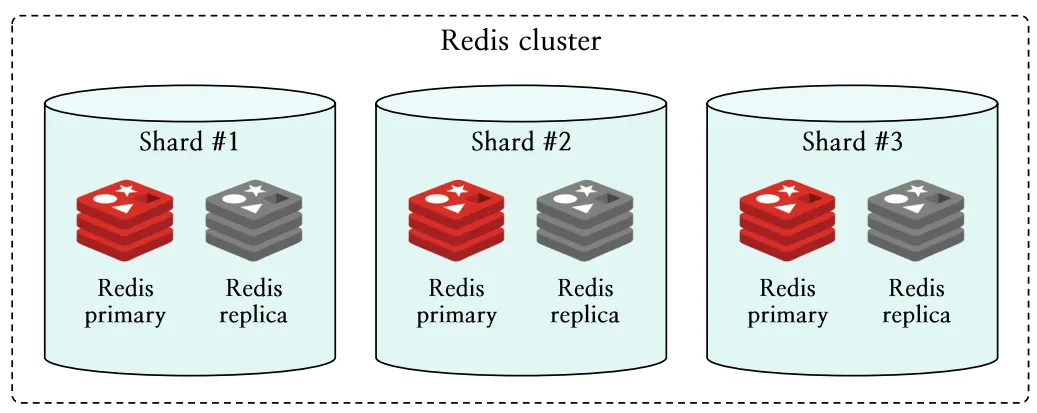
그림 1: Redis Cluster의 기본 구조 도식
•
프라이머리 노드는 샤드에 속한 데이터를 읽고 쓰는 권한을 갖고 있습니다.
•
레플리카 노드는 데이터 읽기만 가능하며, 쓰기 권한은 없습니다.
프라이머리 노드에 장애가 발생하여 다운되면, 동일한 샤드 내의 레플리카 노드 중 한 대가 프라이머리 노드로 위임됩니다. 이를 통해 시스템의 고가용성과 확장성을 이룩할 수 있습니다.
1-2. Hash Slot
Redis Cluster의 각 키는 해시 함수를 통해 총 16,384개의 가상 공간으로 구성된 슬롯에 매핑됩니다. 실제 데이터는 해당 슬롯을 소유하는 샤드에 저장되고, 이 방식으로 데이터를 여러 샤드에 분산시킴으로써 처리 성능과 확장성을 향상시킬 수 있습니다.
16,384개의 슬롯은 총 샤드의 개수로 나눈 크기만큼 각 샤드에 순서대로 할당됩니다. 그림 2는 해시 슬롯을 통해 키를 샤드에 할당하는 과정을 나타냅니다.
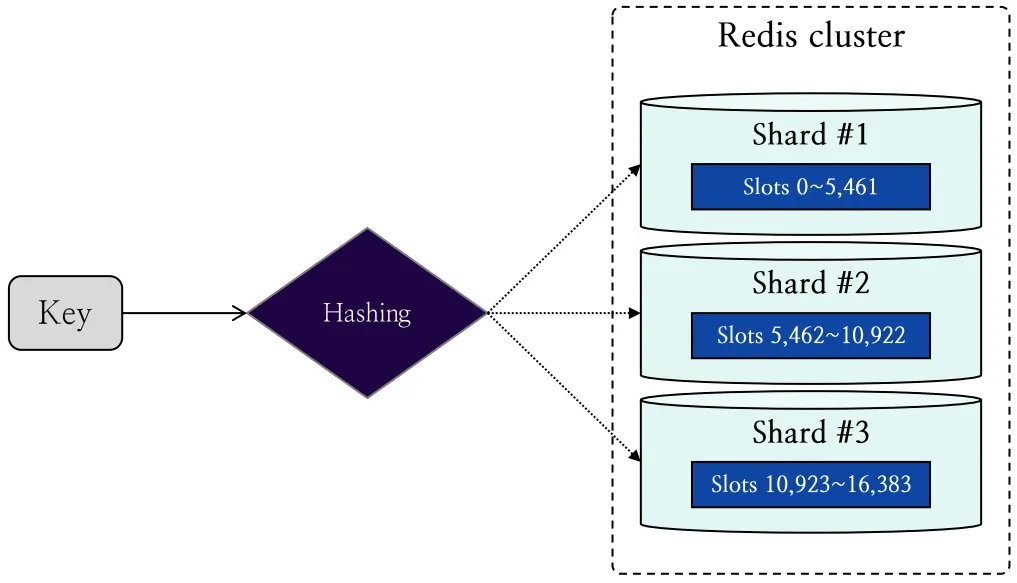
그림 2: Redis Cluster가 해시 슬롯을 통해 키를 샤드에 할당하는 과정 도식화
예를 들어 세 개의 샤드가 존재할 때, 샤드에 할당된 해시 슬롯의 크기는 16,384를 3으로 나눈 값인 5,461이 되며, 각 샤드는 그림과 같이 고유한 슬롯 범위를 갖게 됩니다.
이 수식을 통해 키는 항상 동일한 슬롯을 갖게 되며, 더 나아가 키가 할당되는 샤드를 계산할 수 있습니다.
1-3. Hash Tag
Redis Cluster 환경에서 동일한 키는 항상 동일한 샤드에게 할당됩니다. 하지만 서로 다른 키를 반드시 같은 샤드에 할당해야 하는 특수 상황이 존재할 수 있는데, 예를 들어 MSET, MGET과 같이 한 번에 여러 개의 키를 동시에 설정하거나 조회하는 경우, 반드시 단일 샤드에 존재해야 명령어를 호출할 수 있습니다.
해시 태그 (hash tag)는 특정 조건에서 키를 동일한 해시 슬롯에 매핑하도록 하는 방법입니다. 일반적으로 사용자가 입력한 키는 전체 문자열을 기반으로 해시 슬롯을 매핑하지만, 해시 태그를 사용하면 키의 일부 문자열을 대상으로 해시 슬롯에 매핑할 수 있습니다.
해시 태그를 사용하려면 대상 문자열을 중괄호로 감싸주면 됩니다. 예를 들어, “hello”라는 문자열을 해시 태그로 지정하려면 다음과 같이 키를 작성할 수 있습니다.
•
atcs_message_stream:registration:{hello}
•
atcs_message_stream:ready:{hello}
•
atcs_message_stream:finished:{hello}
이처럼 같은 해시 태그 값을 갖는 키들은 동일한 해시 슬롯 값을 갖게 되어 하나의 샤드에 할당할 수 있습니다. 이를 통해 데이터 로컬리티 (data locality)를 높일 수 있습니다.
2. Redis Streams
Redis Streams는 Redis 5.0부터 지원하는 이벤트 스트리밍을 위한 자료 구조로, 메시징, 이벤트 소싱, 실시간 데이터 처리 등 다양한 분야에서 활용 가능한 플랫폼을 제공합니다.
2-1. 특징
Redis Streams는 프로듀서 (producer), 메시지 큐 (message queue) 그리고 컨슈머 (consumer)로 이루어져 있습니다. 메시지 큐 하나에는 다중 프로듀서 및 컨슈머가 접근할 수 있습니다.
그림 3은 이벤트 스트리밍의 기본적인 구조를 나타냅니다.
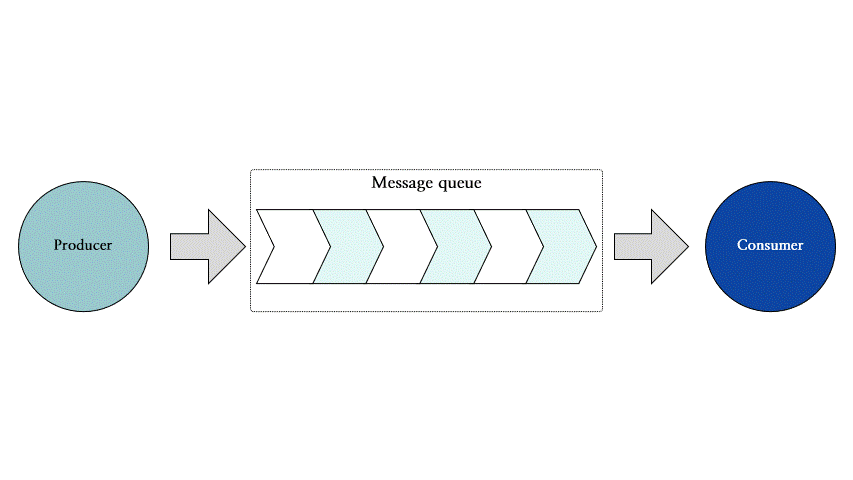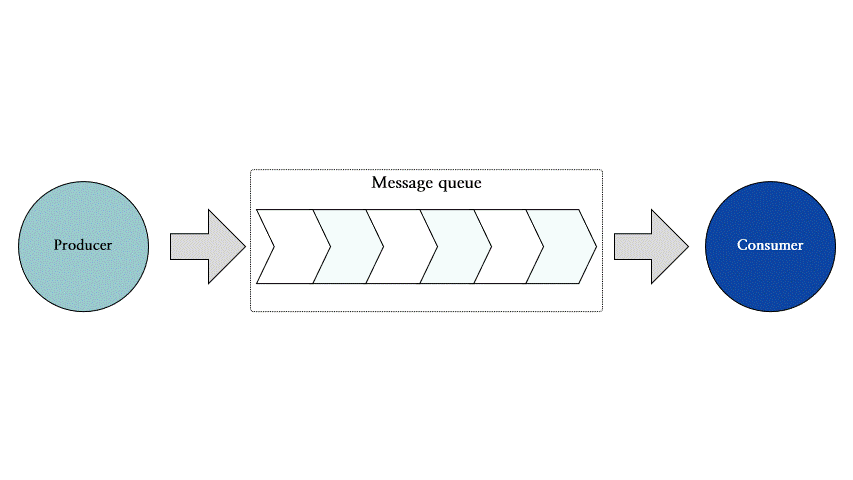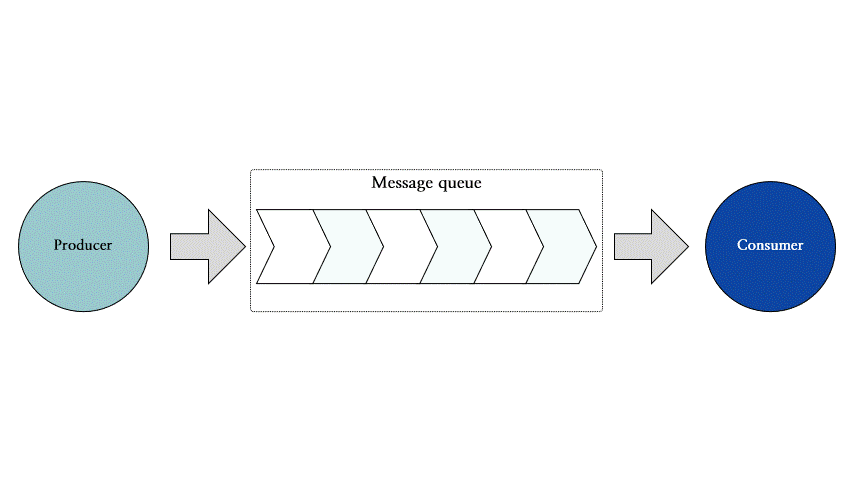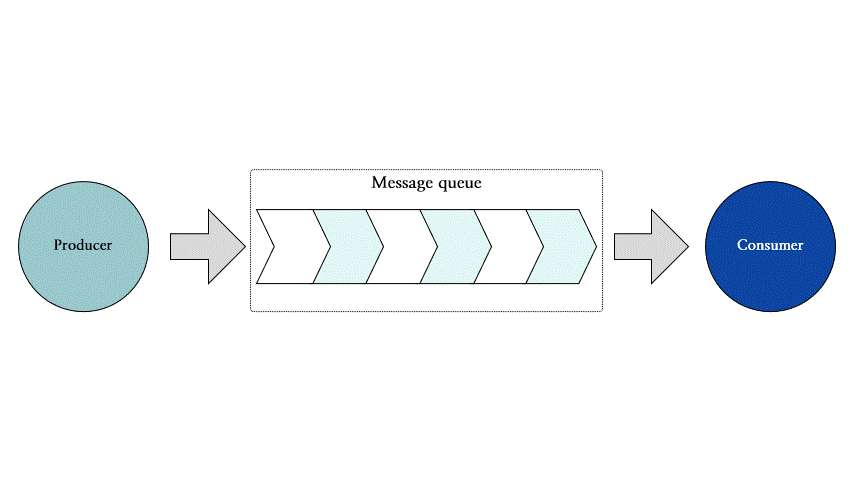
그림 3: 이벤트 스트리밍의 기본 구조 도식
각 구성 요소의 역할은 다음과 같습니다:
•
프로듀서: 이벤트 메시지를 생성하고 메시지 큐에 등록합니다.
•
메시지 큐: 프로듀서가 메시지를 등록하고 컨슈머가 메시지를 가져갈 수 있는 이벤트 메시지 스트림입니다. 하나의 메시지 큐에는 여러 프로듀서와 컨슈머가 존재할 수 있습니다.
•
컨슈머: 메시지 큐에서 이벤트 메시지를 가져와 원하는 작업을 수행합니다.
Redis Streams는 여러 컨슈머가 스트림을 공유하면서 메시지를 중복 없이 소비할 수 있도록 컨슈머 그룹 (consumer group)을 지원합니다. 그룹 내의 컨슈머들은 서로 다른 메시지를 처리하며, 동일한 그룹 내에서 메시지 중복 처리가 발생하지 않습니다.
다음은 컨슈머 그룹의 주요 특징입니다:
•
병렬 메시지 처리: 이벤트 메시지는 컨슈머 그룹 내 컨슈머들에게 균등하게 분배하며, 이를 통해 메시지 처리 속도가 향상되고 처리량이 증가합니다.
•
메시지 오프셋 관리: 컨슈머 그룹은 컨슈머들이 읽은 마지막 메시지의 오프셋을 기록해두며, 이를 통해 메시지 중복 처리나 누락을 방지합니다.

2-2. 한계
유감스럽게도 Redis Streams는 Redis Cluster 환경에서 한 가지 한계점이 있습니다.
동일한 키는 항상 동일한 샤드에서 처리된다는 Redis의 규칙 때문에, Redis Cluster 환경에서 샤드가 아무리 많더라도 하나의 스트림은 항상 동일한 샤드에서 처리됩니다. 이는 Redis Streams가 현재 확장성을 위한 기능을 갖추지 못한 상태라는 것을 의미합니다.
다음 그림 4는 Redis Cluster 환경에서 다중 프로듀서와 컨슈머가 하나의 스트림에 대해 이벤트 메시지를 처리하는 과정의 예시를 나타냅니다.
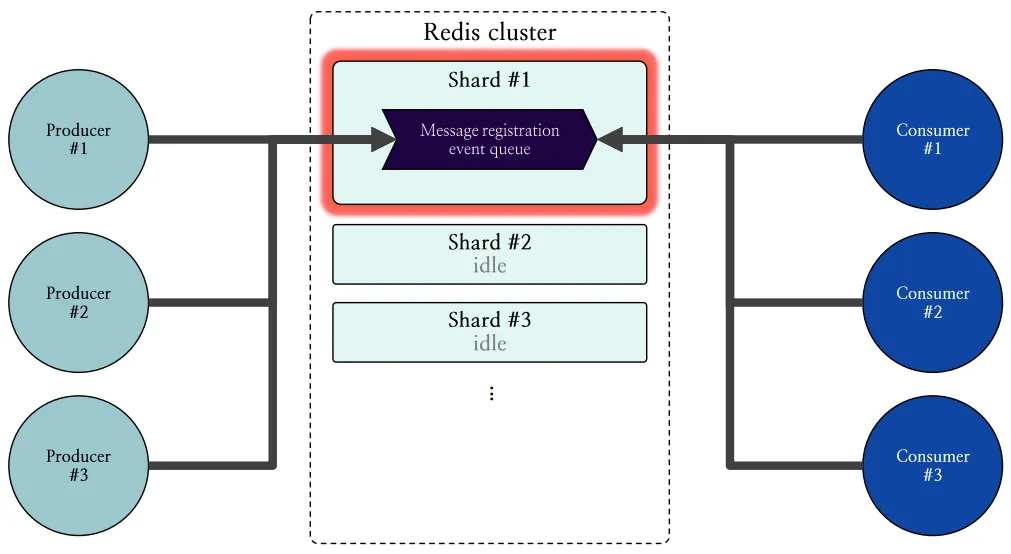
그림 4: 스트림이 속한 샤드에만 트래픽이 집중되는 현상 도식화
그림과 같이 여러 프로듀서들이 메시지 등록 이벤트 큐가 속한 샤드 #1에 메시지를 등록하고 있고, 여러 컨슈머들이 마찬가지로 샤드 #1로부터 메시지를 가져가고 있습니다. 이로 인해 샤드 #1에만 높은 부하가 발생하게 되며, 샤드 #2, 샤드 #3과 같이 다른 샤드들은 idle 상태에 놓이면서 아무런 부하를 받지 않고 부하의 불균등한 상태가 지속될 수 있습니다.
2-3. Apache Kafka와의 비교
특징 | Redis Streams | Apache Kafka |
데이터 모델 | 스트림 | 토픽, 파티션 |
데이터 영속성 | 데이터는 메모리에 저장되며 디스크로의 선택적 영속화 가능 | 데이터는 디스크에 저장됨 |
메시지 순서 보장 | 스트림 내에서 순서 보장 | 파티션 내에서 순서 보장 |
확장성 | 제한적 확장성 (클러스터 내에서 샤드당 하나의 스트림) | 파티셔닝을 통한 높은 확장성 |
내결함성 | 복제 및 장애 조치를 통한 고가용성 | 복제 및 리더 선출을 통한 고가용성 |
컨슈머 그룹 관리 | 명시적인 승인(ACK)을 통한 컨슈머 그룹 관리 | 오프셋 추적 및 리밸런싱을 통한 컨슈머 그룹 관리 |
지연 시간 | 인메모리 작업으로 인해 매우 낮은 지연 시간 | 낮은 지연 시간, 그러나 인메모리 솔루션보다는 높음 |
처리량 | 높은 처리량, 하지만 메모리 용량에 따라 달라질 수 있음 | 매우 높은 처리량 |
운영 복잡성 | 중간 수준 - Redis 클러스터와 스트림 관리를 요구 | 높은 수준 - Kafka 브로커, ZooKeeper 및 토픽 관리를 요구 |
3. Redis SPAR
3-1. 개요
앞서 설명드린 Redis Streams의 확장성 한계를 극복하기 위해 저희는 Redis SPAR (Stream Partition Automatic Rebalancer) 라이브러리를 자체 개발하기로 하였습니다. Redis SPAR는 클러스터 환경에서 다음의 기능을 제공하는 것을 목표로 합니다:
•
스트림 파티셔닝: 사용자가 동일한 목적을 갖는 스트림을 생성하더라도 해당 스트림을 모든 샤드에서 균일하게 처리하도록 스트림 파티셔닝 기능을 제공합니다.
•
컨슈머 파티셔닝 및 리밸런싱: 스트림의 컨슈머 그룹에 신규 컨슈머가 가입하면 가장 적은 수의 컨슈머를 보유한 파티션에 할당되도록 하며, 지속적인 파티션 리밸런싱을 통해 모든 파티션이 항상 균일한 수의 컨슈머를 보유하도록 파티션의 상태를 관리합니다.
3-2. 스트림 파티셔닝
Redis SPAR는 모든 샤드에 부하를 균일하게 분산시키기 위해 파티셔닝 기법을 사용합니다. 파티셔닝 기법은 스트림에 등록되는 메시지를 여러 샤드에 분배하여 처리하는 것으로, 이를 위해서는 프로듀서가 메시지를 모든 샤드에 균일하게 등록하고, 컨슈머가 모든 샤드로부터 메시지를 균일하게 가져갈 수 있어야 합니다.
Redis SPAR의 스트림 파티셔닝 기법을 쉽게 이해할 수 있도록 스트림의 구조를 사용자 관점, 논리적 관점 그리고 물리적 관점의 세 단계로 나누어 설명드리겠습니다.
1. 사용자 관점의 스트림
사용자 관점에서 이벤트 스트리밍 플랫폼의 기본적인 구조는 그림 5와 같습니다.
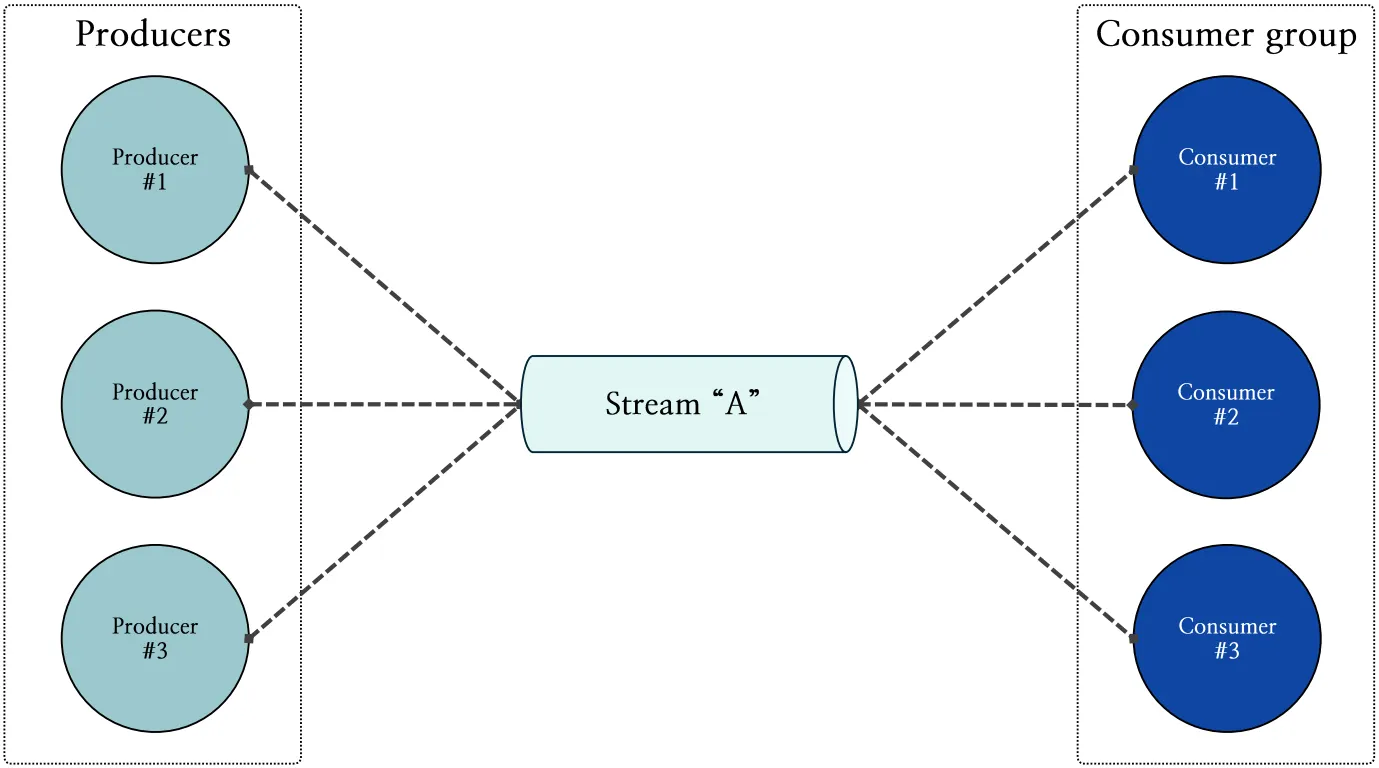
그림 5: 사용자 관점에서 도식화한 스트림 파티셔닝 구조
하나의 스트림에는 다수의 프로듀서와 컨슈머가 메시지를 주고받을 수 있습니다. 또한, 컨슈머 그룹을 생성함으로써 그룹 내 컨슈머들은 메시지를 병렬적으로, 그리고 중복 없이 처리할 수 있습니다. 사용자는 Redis SPAR 내부의 동작 방식을 알 필요 없이 하나의 스트림으로 메시지를 주고받을 수 있다고 믿습니다.
2. 논리적 관점의 스트림
논리적인 관점에서 Redis SPAR의 스트림은 확장성을 확보하기 위해 파티셔닝 기법을 사용합니다. 그림 6은 논리적 관점에서 스트림 파티셔닝 구조를 나타냅니다.
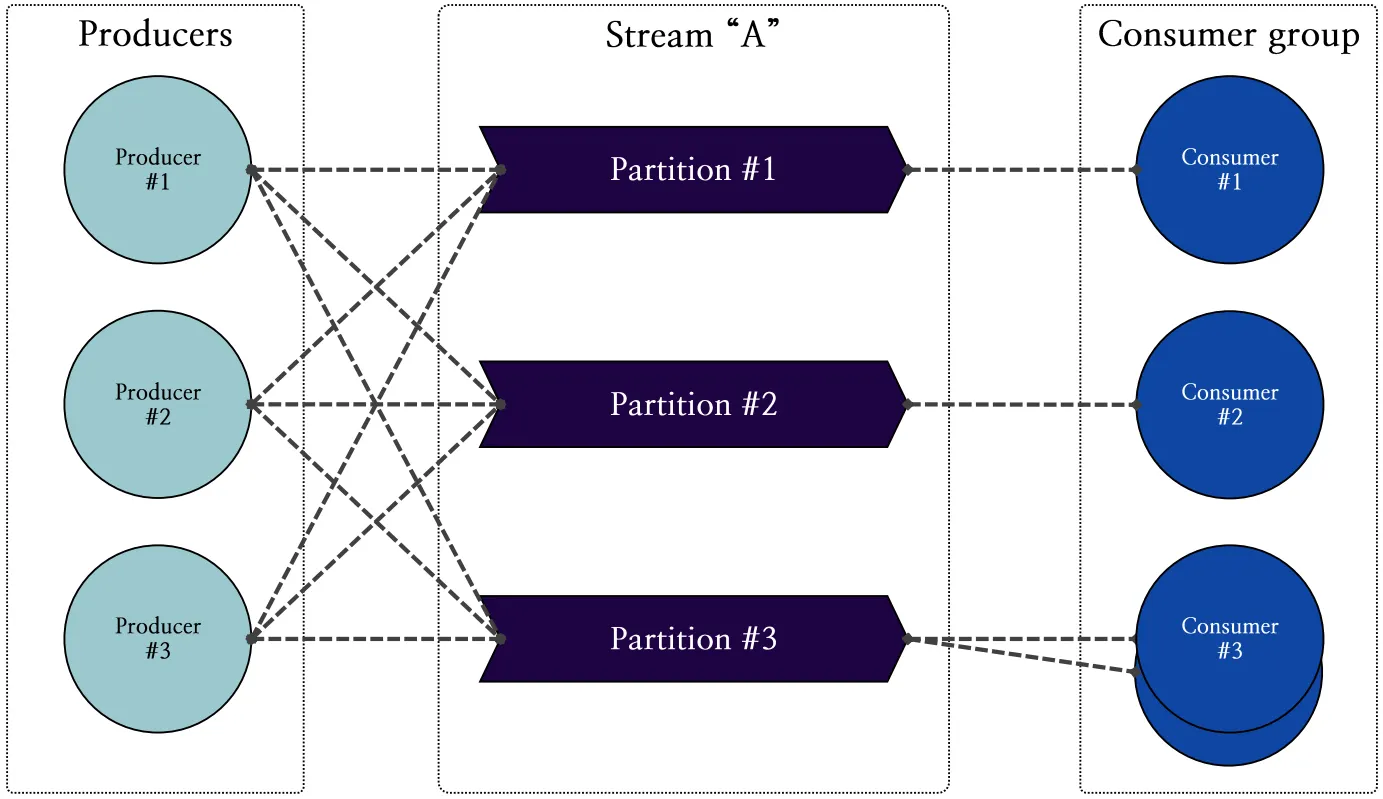
그림 6: 논리적 관점에서 도식화한 스트림 파티셔닝 구조
다수의 프로듀서가 생성한 메시지는 여러 파티션에 균등하게 분배 및 저장되며, 컨슈머 그룹 내의 여러 컨슈머들은 각각의 파티션에 균일하게 할당되어 해당 파티션의 메시지를 가져갑니다. 이러한 파티셔닝 기법을 통해 프로듀서에 의해 발생되는 부하가 증가하더라도 파티션 및 컨슈머를 스케일 아웃 (scale out) 함으로써 과부하 문제를 극복할 수 있습니다.
3. 물리적 관점의 스트림
Redis SPAR는 논리적인 관점에서 살펴본 파티셔닝 기법을 물리적인 관점에서 이룩하기 위해 샤드 별로 스트림을 생성한 후 이를 논리적으로 하나의 스트림 형태로 묶어 관리하는 방식을 취합니다.
그림 7은 “A”라는 논리적인 스트림에 파티셔닝 기법을 적용하기 위해 샤드 별로 하위 스트림을 생성한 모습을 나타냅니다. 그림에서 스트림은 세 개의 샤드를 사용하고 있으며, 샤드 #1에는 “A-1” 스트림, 샤드 #2에는 “A-2” 스트림 그리고 샤드 #3에는 “A-3” 스트림을 생성합니다.
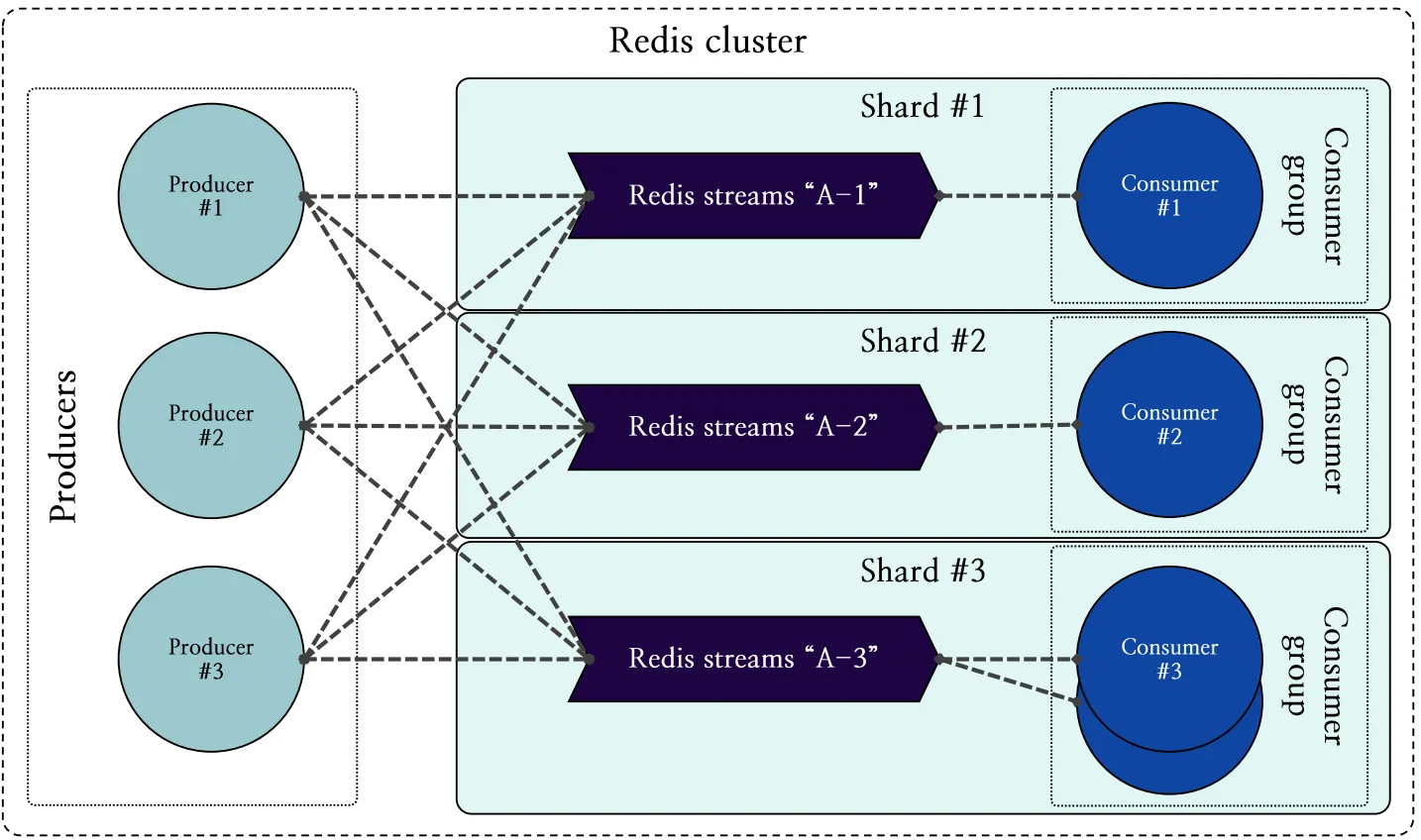
그림 7: 물리적 관점에서 도식화한 스트림 파티셔닝 구조
또한, 하위 스트림마다 컨슈머 그룹을 생성하고 컨슈머들은 할당된 샤드의 컨슈머 그룹에 가입하여 스트림의 메시지를 병렬적으로 가져갈 수 있습니다.
4. 해시 태그 기반의 파티셔닝
Redis SPAR는 원하는 샤드의 스트림을 대상으로 프로듀서가 메시지를 등록하고, 컨슈머가 메시지를 가져가도록 만들기 위해 샤드 키 (shard key)를 사용합니다. 샤드 키는 해시 태그와 함께 사용하여 원하는 샤드에 데이터를 저장할 수 있도록 만들어주는 조력자 역할을 합니다. 예를 들어, 샤드 키가 매핑되는 샤드를 다음 표와 같이 알고 있다고 가정해 보겠습니다.
Shard key | Mapping shard |
AAA | #1 |
BBB | #2 |
CCC | #3 |
해시 태그의 값으로 샤드 키를 사용함으로써 프로듀서는 원하는 샤드에 해당 메시지를 등록할 수 있습니다. 그림 8은 각각의 샤드 키를 해시 태그에 추가함으로써 데이터를 저장할 샤드를 지정하는 과정을 나타냅니다.
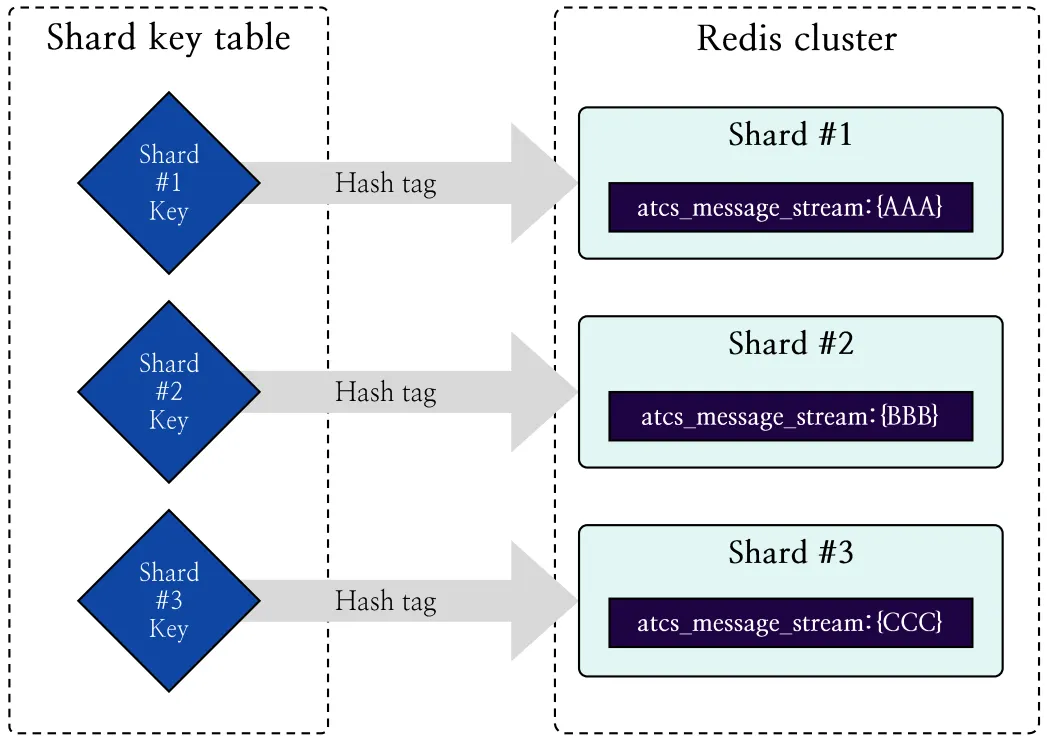
그림 8. 샤드 키를 해시 태그에 추가함으로써 샤드를 지정하는 과정 도식화
Redis SPAR는 샤드 키를 미리 계산하여 테이블로 보관합니다. 그리고 프로듀서가 메시지를 등록할 때, 또는 컨슈머가 메시지를 가져갈 때, 테이블에서 해당 샤드 키를 가져와 해시 태그와 함께 스트림 키에 추가함으로써 원하는 샤드를 지정할 수 있습니다.
3-3. 컨슈머 파티셔닝 작업 위임
Redis SPAR는 컨슈머 그룹 내 신규 컨슈머가 가입하거나 기존 컨슈머가 탈퇴할 때 항상 여러 파티션에 균일한 부하 상태를 유지하도록 파티션 할당 및 리밸런싱 기법을 적용하고 있습니다. Redis SPAR에는 이러한 작업을 위한 역할인 코디네이터 (coordinator)가 부재하므로, 컨슈머에게 역할을 직접 부여하고 작업을 위임하는 기법을 사용합니다.
Redis Streams와 유사한 이벤트 스트리밍 플랫폼인 아파치 카프카 (Kakfa)에서 코디네이터는 컨슈머 그룹 관리, 파티션 할당 및 오프셋 관리를 수행합니다.
1. 컨슈머 유형
컨슈머 파티셔닝과 관련된 작업을 위임하기 위해 Redis SPAR는 컨슈머를 두 유형으로 구분합니다.
•
리더 (leader) 컨슈머: 신규 컨슈머의 파티션 할당 및 파티션 리밸런싱 작업을 주도합니다.
•
팔로워 (follower) 컨슈머: 리더 컨슈머에 의해 할당된 파티션에서 메시지를 가져와 처리합니다.
컨슈머 그룹의 모든 컨슈머는 팔로워 컨슈머가 되며, 그중 하나는 리더 컨슈머로 선출됩니다.
2. 리더 컨슈머 선출 방식
락킹 메커니즘은 주로 분산 환경에서 여러 노드가 동시에 같은 데이터에 접근할 때 발생할 수 있는 무결성 문제를 해결하기 위해 사용됩니다.
이 메커니즘을 적용한 Redis SPAR에는 리더 컨슈머로서의 자격을 증명해 주는 리더 락 (leader lock)이 존재하며, 모든 컨슈머들은 리더가 되기 위해 리더 락의 획득을 시도합니다. 그림 9는 네 개의 컨슈머들이 리더 락을 획득하는 과정을 나타냅니다. 이 예시에서는 컨슈머 #1이 가장 먼저 락을 획득하여 리더 컨슈머로 선출되었으며, 이후에 요청한 컨슈머들은 리더 락을 획득하는 데 실패한 상황을 묘사합니다.
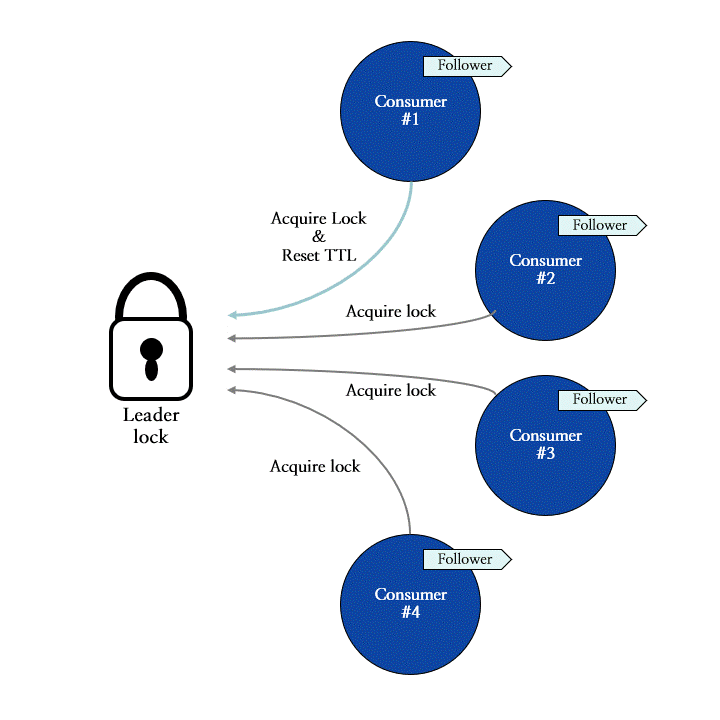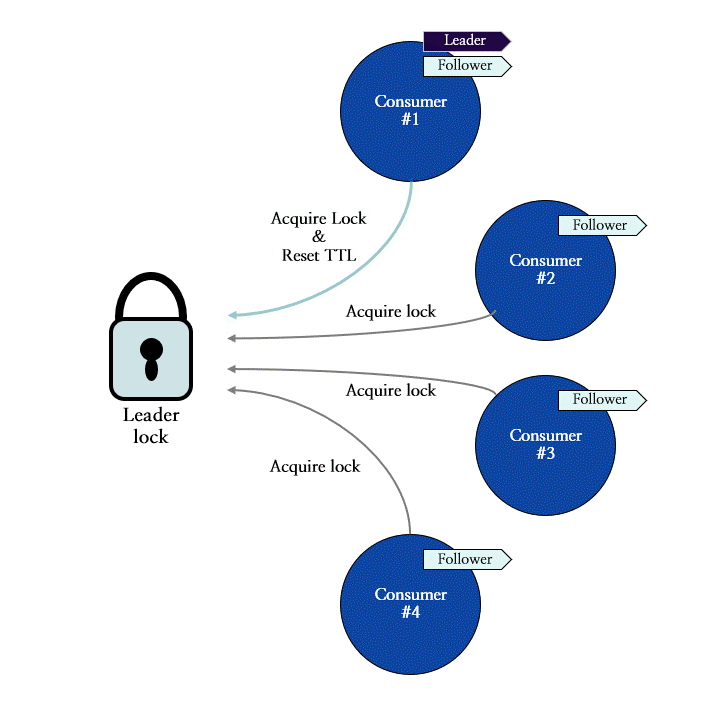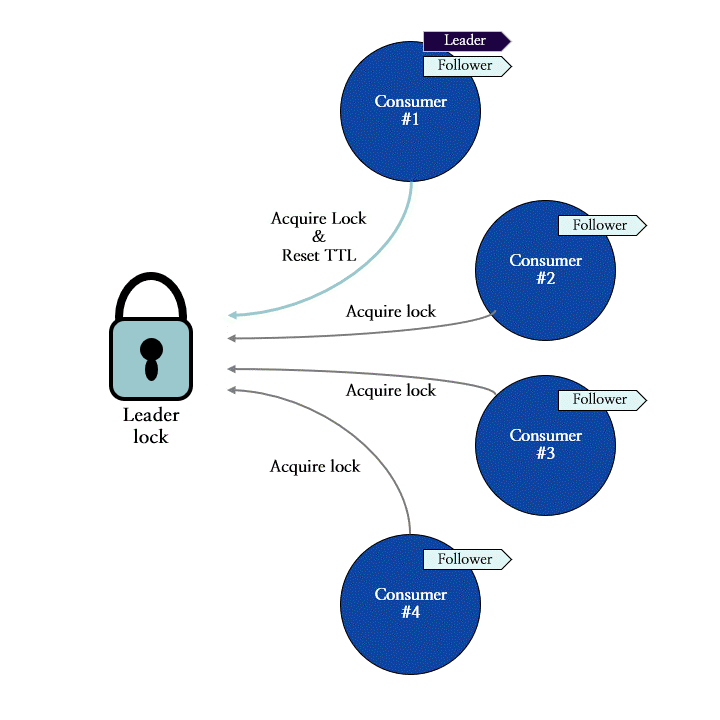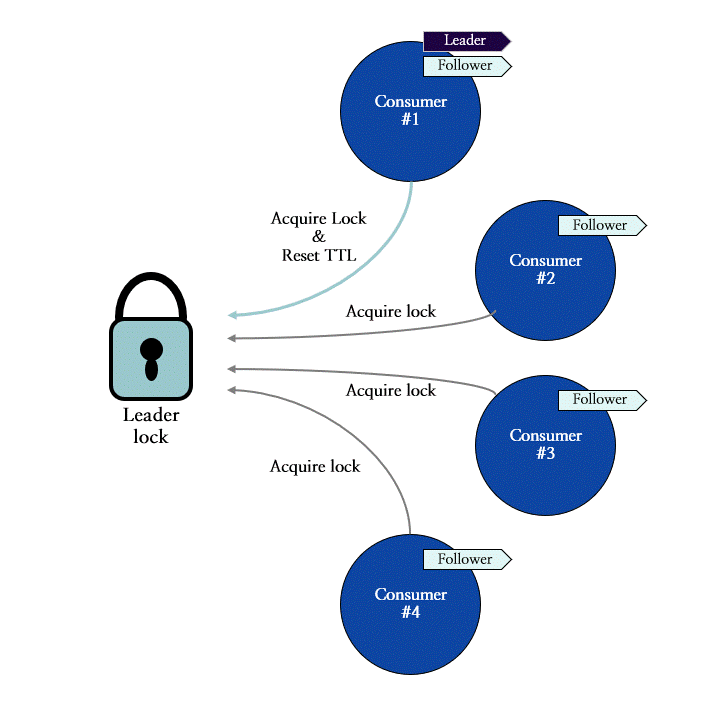
그림 9: 리더 락 획득을 통한 리더 컨슈머의 선출 과정 도식화
Redis SPAR가 등록하는 리더 락에 대한 키 형식은 다음과 같습니다:
{atcs_message_stream:$스트림}:consumer_group:$컨슈머그룹:lock:leader
Plain Text
복사
리더 락에는 TTL (Time To Live) 메커니즘이 적용되어 일정 시간 내에 키를 갱신하기 않으면, 락은 타임아웃 발동 후 자동으로 소멸됩니다. 따라서 리더가 된 컨슈머 #1은 지속적으로 리더 락을 갱신하여 리더로서의 자격을 유지해야 합니다. 이러한 TTL 메커니즘을 통해 Redis SPAR는 내결함성을 높일 수 있습니다.
3. 리더 컨슈머와 팔로워 컨슈머 간 통신 수단
신규 컨슈머의 파티션을 할당하고 리밸런싱을 위한 요청을 주고받기 위해 리더 컨슈머와 팔로워 컨슈머 사이에는 통신 수단이 필요합니다. 이를 위해 Redis SPAR는 Publish-subscribe pattern의 구현체인 Redis Pub/Sub을 활용합니다.
컨슈머 그룹은 (1) 리더 컨슈머가 팔로워 컨슈머에게 메시지를 전달하기 위한 팔로워 채널과 (2) 팔로워 컨슈머가 리더 컨슈머에게 메시지를 전달하기 위한 리더 채널을 갖습니다. 그림 10은 리더 컨슈머와 팔로워 컨슈머 사이의 Redis Pub/Sub을 활용한 통신 구조를 나타냅니다.
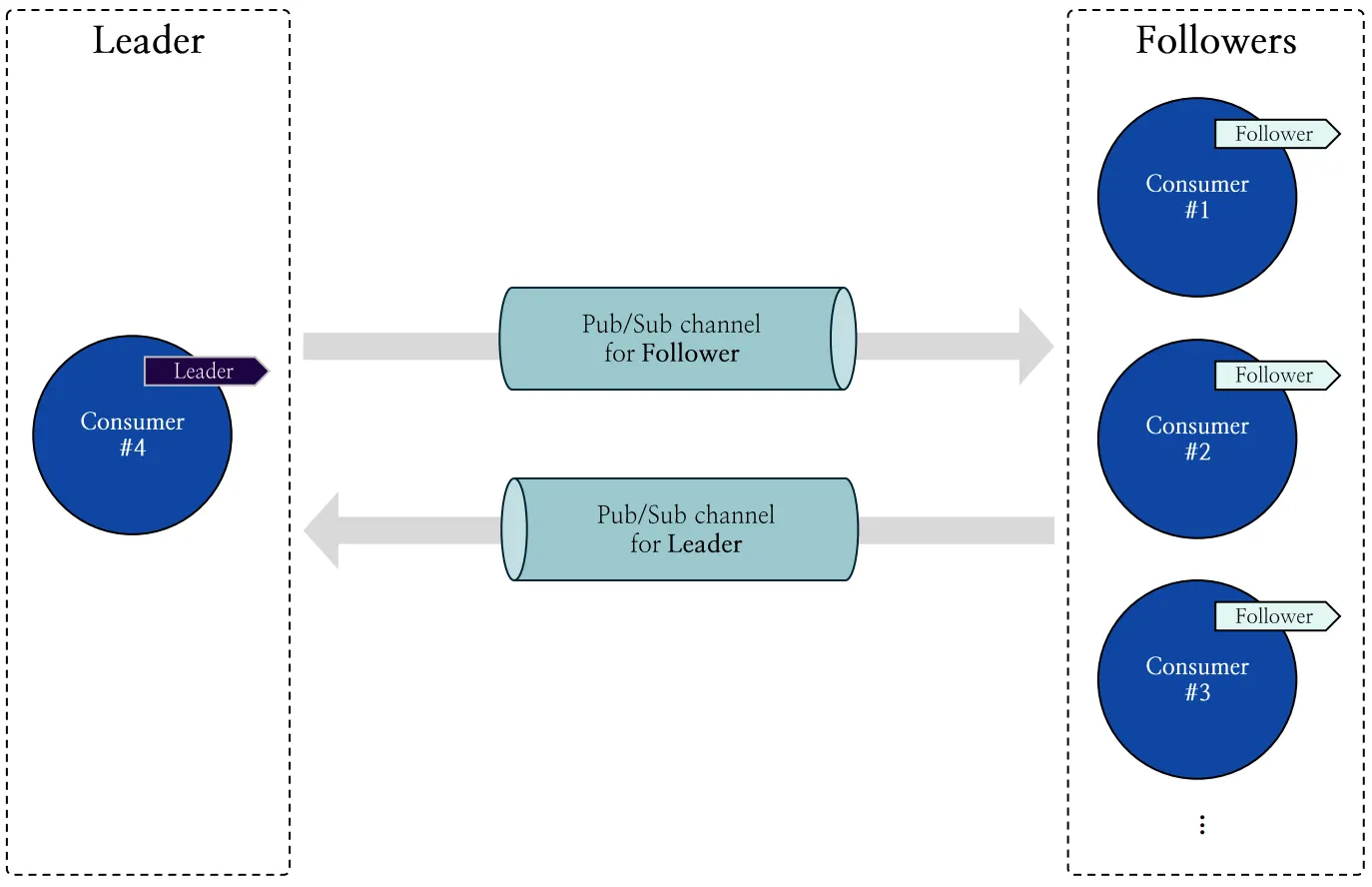
그림 10: 리더 컨슈머와 팔로워 컨슈머 사이의 Pub/Sub 기반 통신 구조 도식화
리더 채널
리더 채널에서 팔로워 컨슈머가 리더 컨슈머에게 보내는 주요 요청은 다음과 같습니다:
•
파티션 할당 요청: 신규 팔로워 컨슈머가 파티션 할당을 요청합니다.
•
팔로워 컨슈머 탈퇴 요청: 팔로워 컨슈머가 그룹 탈퇴를 요청합니다.
팔로워 채널
팔로워 채널에서 리더 컨슈머가 팔로워 컨슈머에게 보내는 주요 요청은 다음과 같습니다:
•
파티션 이동 요청: 팔로워 컨슈머에게 파티션 이동을 요청합니다.
•
리더 등록/탈퇴 통보: 신규 리더 컨슈머가 등록 및 기존 리더 컨슈머의 탈퇴 이벤트를 통보합니다.
이 두 채널을 통해 리더와 팔로워 간 효율적인 통신을 이룩할 수 있습니다.
3-4. 컨슈머 파티셔닝 및 리밸런싱
1. 파티션의 상태 정의
스트림 파티션에 할당된 컨슈머 수를 파티션의 크기로 정의할 때, Redis SPAR는 파티션의 크기를 기준으로 균형 상태와 불균형 상태로 스트림 파티션을 구분합니다.
•
균형 (balanced) 상태: 가장 큰 파티션과 가장 작은 파티션의 크기 차이가 1 이하인 상태입니다.
•
불균형 (imbalanced) 상태: 가장 큰 파티션과 가장 작은 파티션의 크기 차이가 2 이상으로, 파티션 리밸런싱이 필요한 시점입니다.
그림 11은 세 개의 스트림 파티션이 균형 상태인 예시를 나타냅니다. 그림과 같이 스트림 파티션이 균형인 상태에서는 리밸런싱이 필요하지 않습니다.
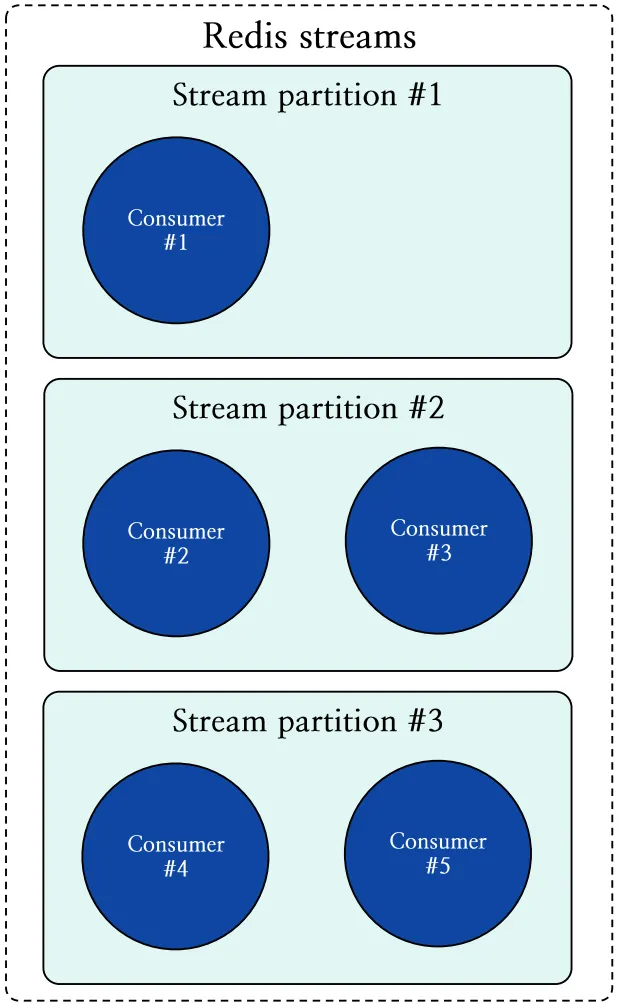
그림 11: 파티션에 팔로워 컨슈머들이 균일하게 할당된 상태 도식화
반면, 그림 12는 스트림 파티션 #1에 속한 컨슈머가 제거되면서 파티션이 불균형 상태가 된 모습을 나타냅니다.
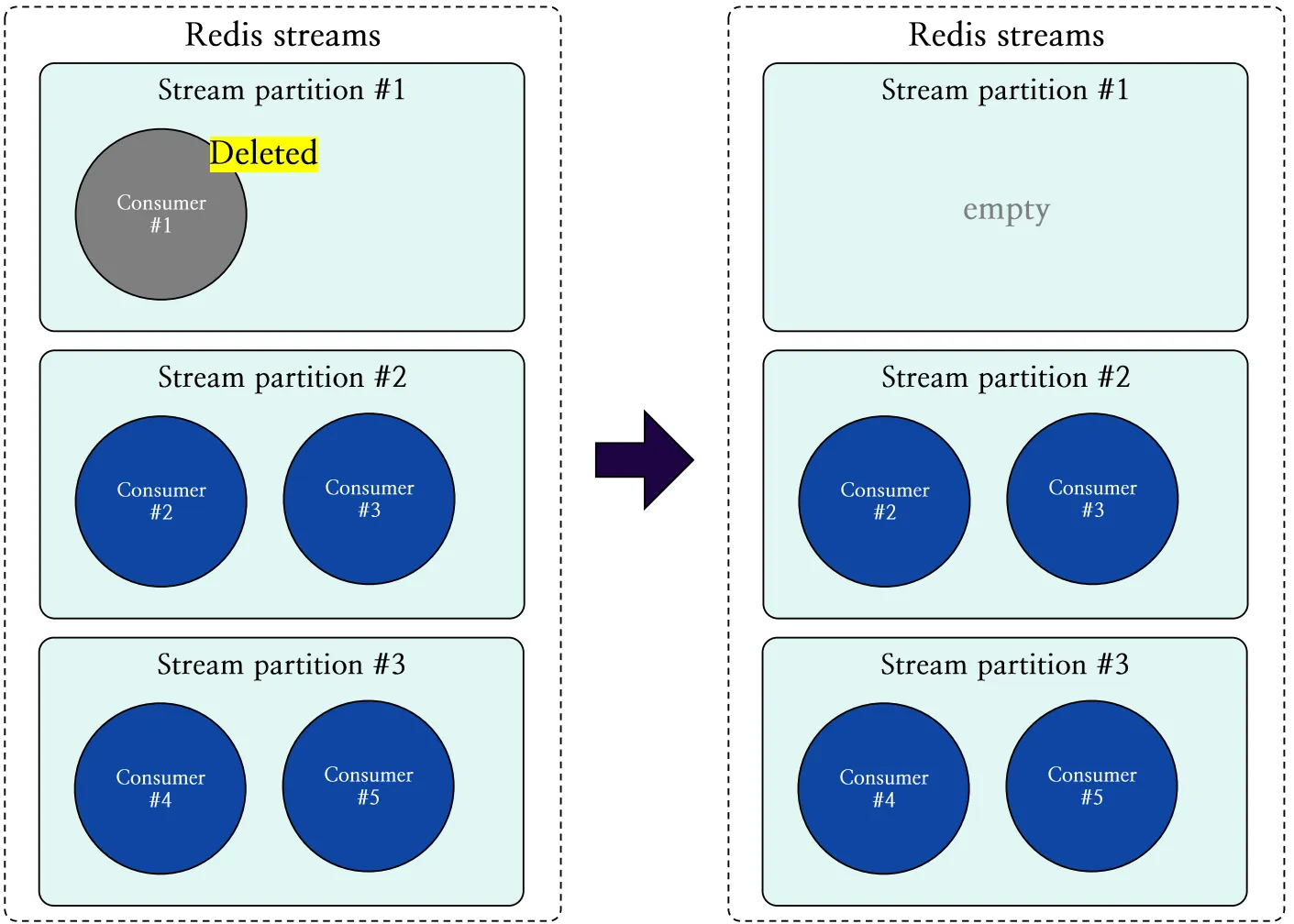
그림 12: 스트림 파티션에 팔로워 컨슈머가 삭제된 후 불균일한 파티션의 상태 도식화
Redis SPAR에서는 스트림 파티션이 불균형 상태에 놓일 경우, 파티션의 리밸런싱이 필요한 시점으로 판단합니다.
2. 컨슈머 파티셔닝
컨슈머 그룹에 신규 팔로워 컨슈머가 가입하면 리더 컨슈머는 해당 컨슈머에 대한 파티셔닝을 수행합니다. 컨슈머 파티셔닝의 동작은 파티션 리밸런싱과 거의 유사하지만 해당 컨슈머에 대해서만 수행이 된다는 점이 다릅니다.
컨슈머 파티셔닝의 간략한 순서는 다음과 같습니다:
1.
파티션 집계: 각 파티션에 할당된 컨슈머 수를 집계합니다.
2.
가장 작은 파티션 추출: 집계된 자료를 바탕으로 가장 작은 파티션을 추출합니다.
3.
컨슈머의 파티션 할당: 신규 팔로워 컨슈머를 가장 작은 파티션에 할당합니다.
컨슈머 파티셔닝에서 파티션 집계, 추출 및 할당 과정은 리밸런싱과 동일한 작업으로, 작업 과정은 해당 부분에서 자세히 살펴봅니다.
신규 팔로워 컨슈머에게 파티션이 할당되면서 다음과 같은 형식의 팔로워 컨슈머 키가 발급됩니다.
{atcs_message_stream:$스트림}:consumer_group:$컨슈머그룹:partition:$파티션:consumer:$컨슈머식별자
Plain Text
복사
발급된 팔로워 컨슈머 키는 이후 리더 컨슈머의 파티션 별 컨슈머 집계 작업을 위해 사용됩니다.
또한, 팔로워 컨슈머 키에는 TTL 메커니즘이 적용되어 있기 때문에 팔로워 컨슈머는 지속적으로 TTL 값을 갱신해주지 않으면 타임아웃 발동 후 자동으로 소멸됩니다. 이러한 메커니즘을 통해 팔로워 컨슈머에 대한 내결함성을 높일 수 있습니다.
3. 파티션 리밸런싱
발동 조건
스트림의 파티션 리밸런싱은 특정 조건이 충족될 때 마다 발동됩니다. 파티션 리밸런싱이 발동되는 조건은 다음과 같습니다:
•
신규 팔로워 컨슈머 가입
•
기존 팔로워 컨슈머 탈퇴
•
리더 컨슈머 교체
•
타임아웃 발동
위 조건 중 하나라도 충족되면 즉시 리밸런싱 작업을 수행합니다.
여러 조건이 동시에 충족되더라도 파티션 리밸런싱은 동시에 수행되지 않습니다.
작업 개요
스트림 파티션의 리밸런싱 작업 순서는 크게 파티션 집계와 파티션 리밸런싱으로 이루어져 있습니다. 그림 13은 파티션 리밸런싱 작업의 순서를 나타냅니다.
.
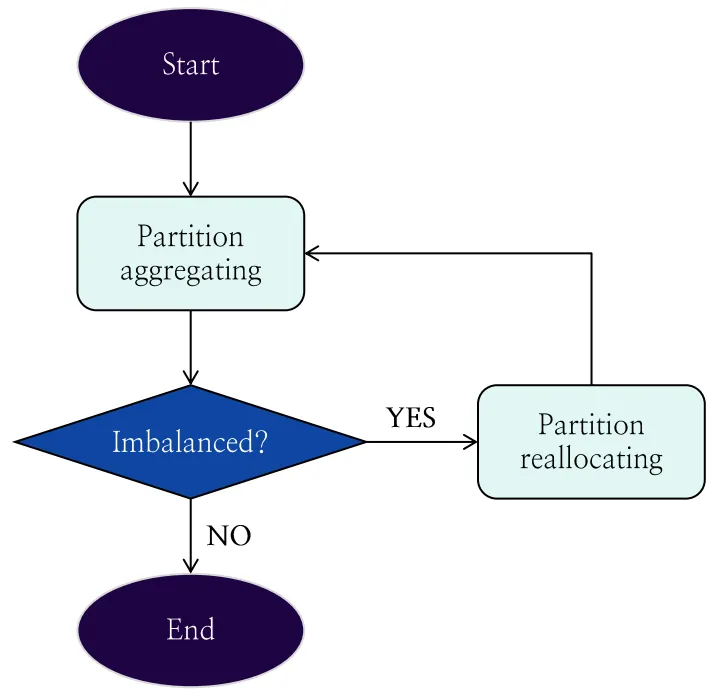
그림 13. 파티션 리밸런싱의 플로우 차트
•
파티션 집계: 각 파티션에 할당된 컨슈머들의 수를 집계합니다.
•
파티션 상태 검사: 파티션들이 균형 상태인지 검사합니다.
•
파티션 재할당: 파티션들을 균형 상태로 만들기 위해 컨슈머의 파티션 재할당을 수행합니다.
파티션 리밸런싱 작업의 세부 단계는 다음과 같습니다.
작업 1: 파티션 집계
파티션 집계 단계에서 각 파티션에 할당된 컨슈머 수를 집계합니다. 집계를 위해 Sorted Set 자료구조를 사용하는데, 이를 통해 가장 큰 파티션과 가장 작은 파티션을 빠르게 조회할 수 있습니다.
작업 2: 상태 검사
작업 1에서 생성한 Sorted Set을 기반으로 가장 큰 파티션과 가장 작은 파티션을 추출하여 크기 차이가 2 이상 벌어질 경우, 리밸런싱 작업 3을 수행하고, 그렇지 않으면 리밸런싱 작업을 종료합니다.
작업 3: 파티션 재할당
작업 2에서 추출한 두 파티션을 활용하여 다음 작업을 수행합니다.
1.
가장 큰 파티션에 속한 임의의 컨슈머를 추출합니다.
2.
추출한 컨슈머를 가장 작은 파티션으로 이동시킵니다.
그림 14는 파티션 재할당 작업을 도식화한 것으로, 가장 큰 파티션 #3에 속한 임의의 컨슈머 #5가 추출되어 가장 작은 파티션 #1로 이동하는 과정을 보여주고 있습니다.
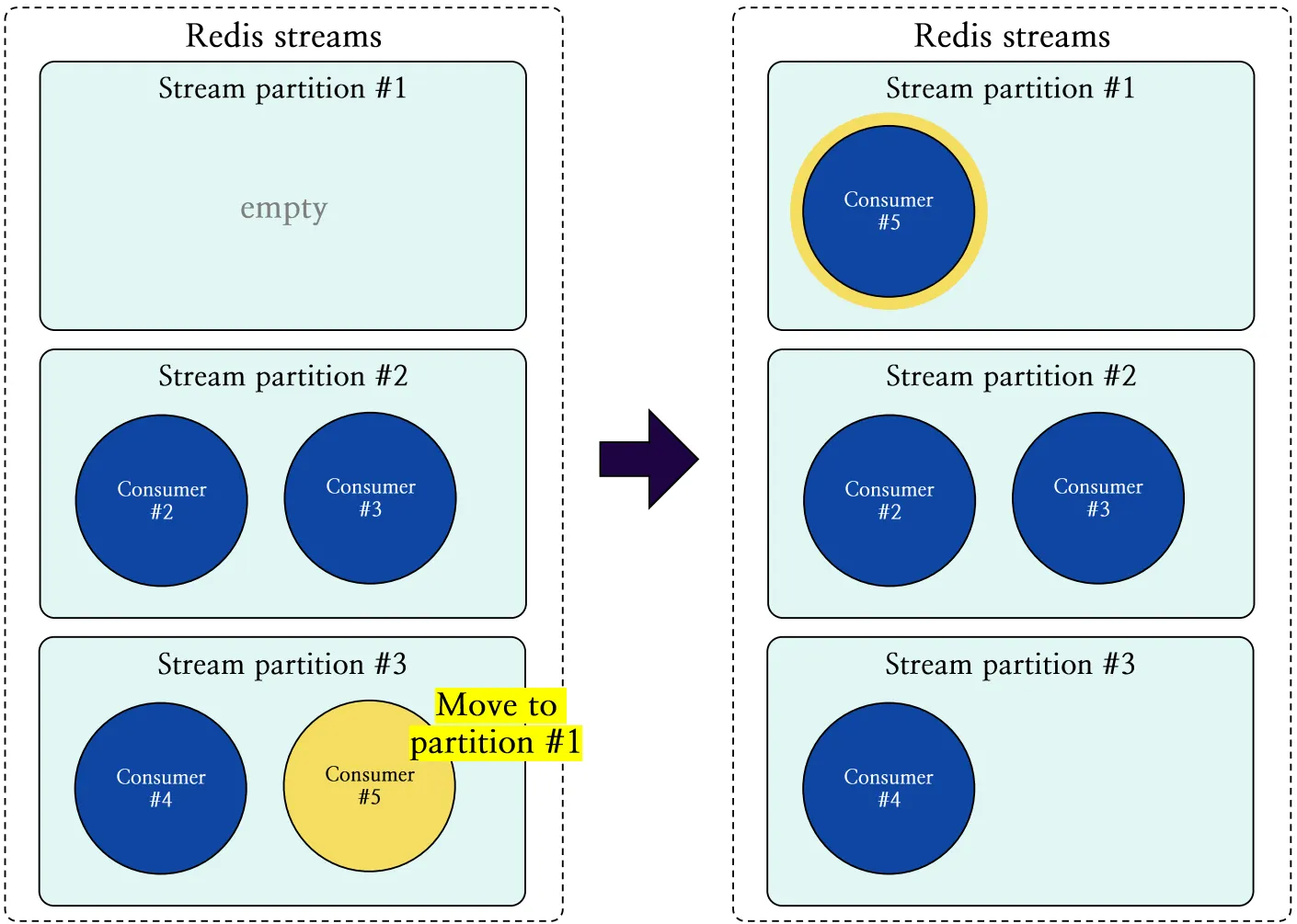
그림 14. 가장 큰 스트림 파티션 내 컨슈머의 가장 작은 파티션으로의 이동 과정 도식화
작업 3을 통해 하나의 컨슈머에 대한 파티션 이동 작업을 완료하게 됩니다.
작업 4. 작업 반복
모든 스트림의 파티션들이 균형 상태가 될 때 까지 리밸런싱 작업 1부터 리밸런싱 작업 3까지를 반복적으로 수행합니다.
4. 성능 테스트
Redis SPAR를 통해 Redis Streams의 파티셔닝 및 리밸런싱이 올바르게 수행되는지 검증하기 위해 성능 테스트를 진행하였습니다.
4-1. 테스트 목표
1. 샤드의 부하 균등 분배 확인
Redis SPAR의 궁극적인 목표는 클러스터 환경에서 단일 스트림의 부하가 모든 샤드에 균등하게 분배되는 것 입니다. 따라서, 이번 성능 테스트를 통해 부하가 가해지는 상황 속에서 Redis SPAR가 적용된 스트림의 부하가 각 샤드에 균등하게 분배되는지 여부를 확인합니다.
2. 스트림 파티셔닝 및 리밸런싱 확인
오토스케일링 (autoscaling) 기능이 적용된 애플리케이션에서 Redis SPAR 라이브러를 기반으로 스트림 메시지를 처리하도록 작업 환경을 구성하고, 다음의 상황에 따른 동작을 확인합니다:
•
스케일 아웃 (scale out) 상황: 스트림에 부하가 가해지면서 스케일 아웃이 발생했을 때, 신규 컨슈머들이 스트림 내 파티션들에 균일하게 할당되었는지 확인합니다.
•
스케일 인 (scale in) 상황: 가해지는 부하가 멈춘 상황에서 스케일 인이 발생했을 때, 최종적으로 남은 컨슈머들이 스트림 내 파티션들에 균일하게 할당되었는지 확인합니다.
4-2. 테스트 환경
1. Amazon ElastiCache
Redis Cluster를 구축하기 위해 Amazon ElastiCache를 사용합니다.
•
샤드 개수: 3대
•
노드 유형: cache.t4g.small
2. nGrinder (Amazon EC2)
부하 테스트에서 호출을 발생시키는 클라이언트를 위해 nGrinder를 사용합니다.
nGrinder는 네이버에서 개발한 오픈 소스 성능 테스트 플랫폼으로, 가상의 사용자를 생성하여 실제 서버에 부하를 가하고, 그 결과를 통해 서버의 성능을 평가할 수 있도록 지원하는 도구입니다.
•
노드 유형: t3.medium
•
에이전트 개수: 15대
•
가상의 유저: 1,920명
3. Amazon EKS
•
최대 노드 개수: 100대
•
노드 유형: c5.xlarge
•
서비스 파드 최소 개수: 9대
•
파드 당 CPU 자원: 1,000m
•
파드 당 메모리 자원: 1Gi
4-3. 테스트 방식
이번 성능 테스트는 NXCommand 서비스를 이용하여 진행하였습니다. NXCommand는 플랫폼과 게임 간의 표준화된 API를 제공하는 플랫폼으로, 자세한 정보는 저번 포스트를 참고 바랍니다.
1. NXCommand에서 스트림 기반 작업
NXCommand 서버는 게임 연동 서버에 명령어를 전송하기 전에 ATCS 스케줄러에게 요청을 보내도 되는지 확인합니다. 이때, NXCommand 서버는 프로듀서로서, 그리고 ATCS 스케줄러는 컨슈머로서 Redis SPAR 라이브러리를 통해 이벤트 메시지를 주고받습니다. 그림 15는 NXCommand 서버와 ATCS 스케줄러가 Redis Streams을 기반으로 ATCS 메시지를 주고받는 과정을 나타냅니다.
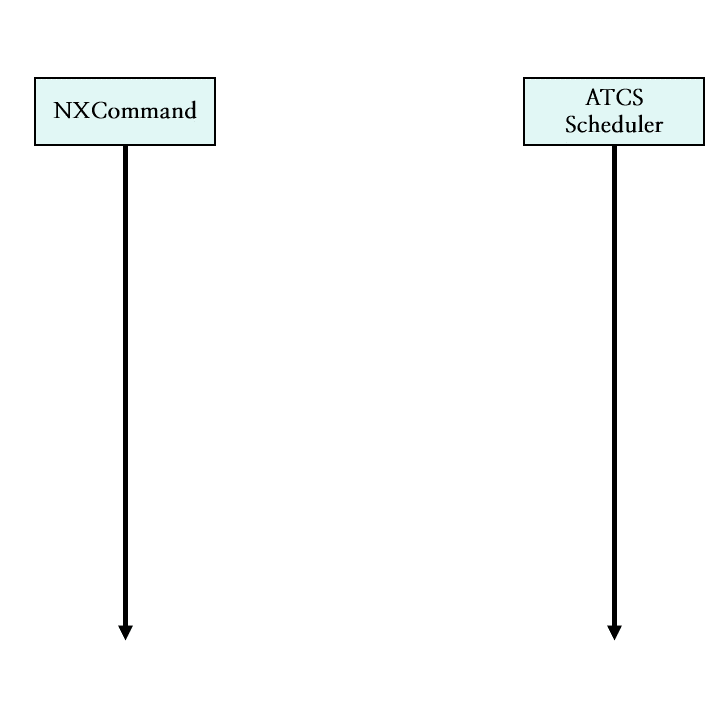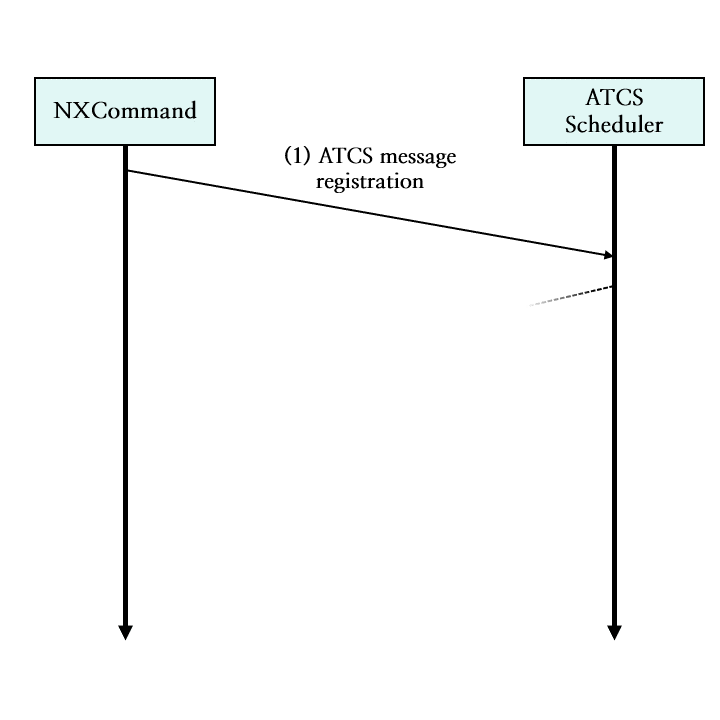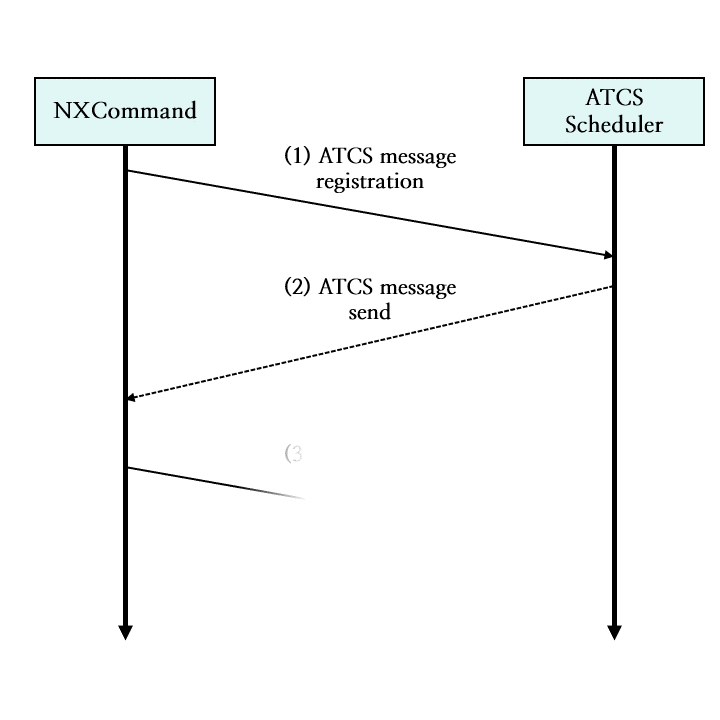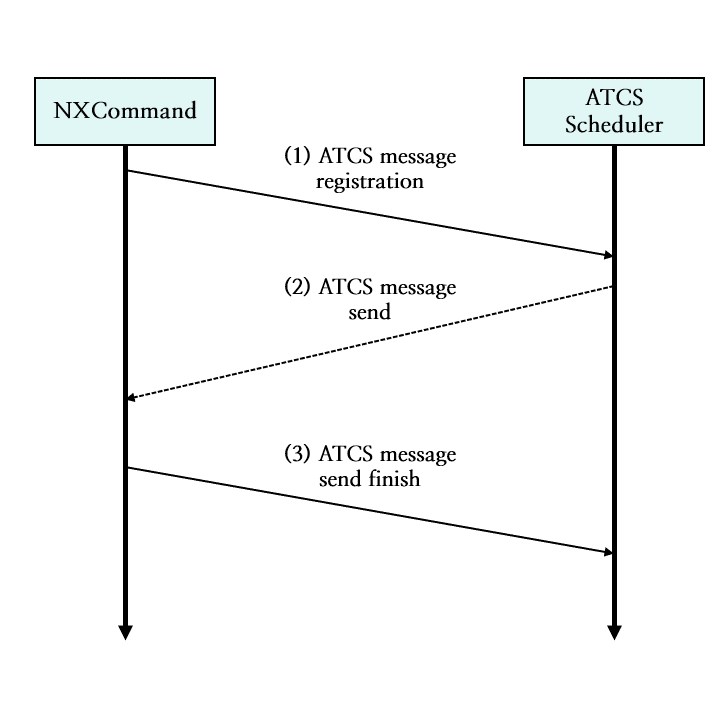
그림 15. NXCommand의 ATCS 메시지 스트림 통신 과정 도식화
1.
NXCommand 서버는 (1) ATCS 메시지 등록 스트림에 메시지를 등록합니다.
2.
ATCS 스케줄러는 (1) ATCS 메시지 등록 스트림으로부터 메시지를 가져와 해당 게임 연동 서버의 트래픽 상태를 검사합니다.
3.
ATCS 스케줄러는 (2) ATCS 메시지 발송 스트림에 메시지를 등록합니다.
4.
NXCommand 서버는 (2) ATCS 메시지 발송 스트림으로부터 메시지를 가져와 게임 연동 서버로 NXCommand 명령어를 호출합니다.
5.
NXCommand 서버는 게임 연동 서버로 명령어 호출을 완료합니다.
6.
NXCommand 서버는 (3) ATCS 메시지 발송 완료 스트림에 메시지를 등록합니다.
7.
ATCS 스케줄러는 (3) ATCS 메시지 발송 완료 스트림으로부터 메시지를 가져와 해당 게임 연동 서버의 트래픽 상태를 갱신합니다.
2. nGrinder의 요청 방식
nGrinder 에이전트 15대에서 생성된 1,920명의 가상 사용자가 15분 동안 NXCommand 서비스에 get_gc_all_by_guid 명령어를 무제한으로 호출합니다. 모든 가상 사용자가 보내는 호출 정보는 동일합니다.
NXCommand 서비스에서 get_gc_all_by_guid 명령어는 계정 식별자를 통해 계정 내 모든 캐릭터 정보를 조회하는 명령어입니다.
4-4. 테스트 결과
1. nGrinder의 호출 결과
nGrinder 에이전트를 통해 호출한 결과는 그림 16과 같습니다.
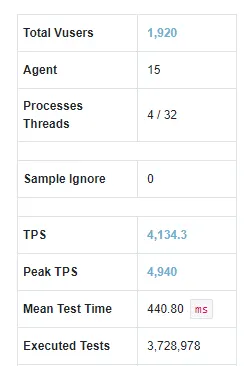
그림 16: nGrinder 호출 통계
15대의 nGrinder 에이전트에서 1,920명의 유저가 15분 동안 호출한 결과, 총 3,728,978건의 호출이 발생했으며, TPS는 평균 4,134건, 최대 4,940건으로 집계되었습니다. 그림 17은 15분 동안 가해진 호출의 TPS 추이를 나타냅니다.
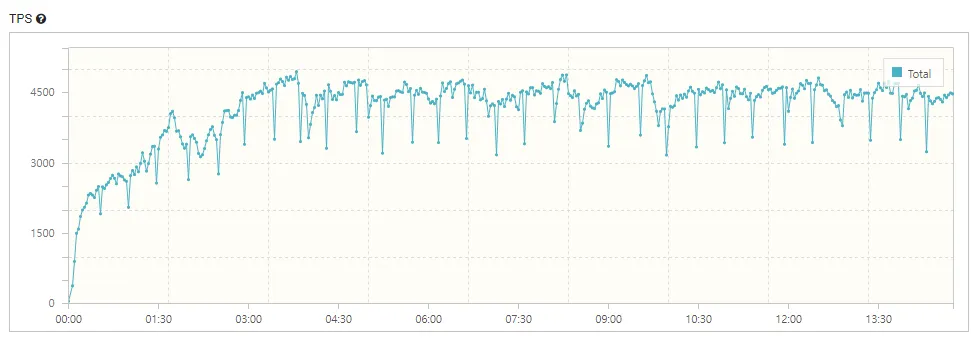
그림 17: 시간 경과에 따른 nGrinder 에이전트의 TPS 추이
2. 스트림 기반 명령어 호출 횟수
부하 테스트를 진행하는 상황에서 ElastiCache의 시간에 따른 샤드 별 스트림 기반 명령어 호출 수는 그림 18과 같이 나타났습니다.
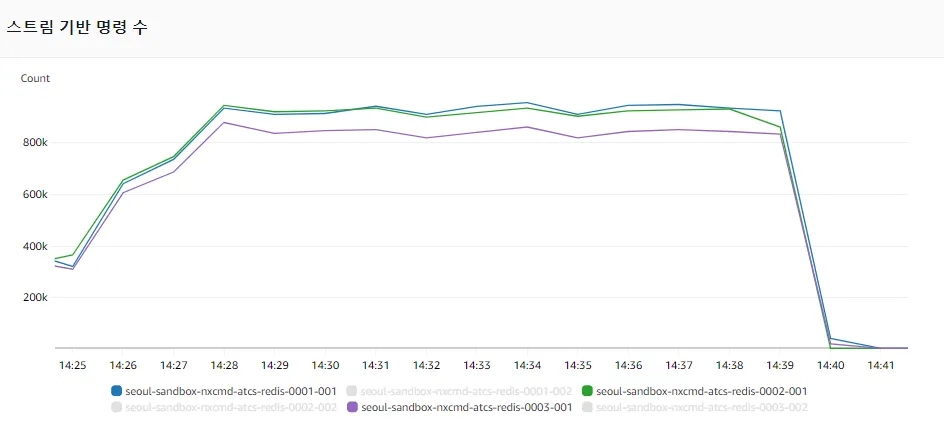
그림 18: Redis Cluster 환경에서 각 샤드의 프라이머리 노드가 스트림 기반 명령어를 균일하게 호출한 모습
그림에서 보는 바와 같이, 모든 샤드의 프라이머리 노드에서 거의 균일한 수의 스트림 기반 명령어를 호출한 것을 확인할 수 있습니다.
샤드의 레플리카 노드는 프라이머리 노드에서 호출된 명령어를 복제하는 용도로만 사용되고 있기 때문에 의미가 없다고 판단하여 그림에서 제외하였습니다.
3. 오토스케일링 과정에서 파티션 할당 분포 - 스케일 아웃
부하가 가해지는 상황 속에서 ATCS 스케줄러와 NXCommand 서버는 그림 19와 같이 처음 9대에서 각각 65대와 61대까지 파드 수가 점진적으로 증가하였습니다.
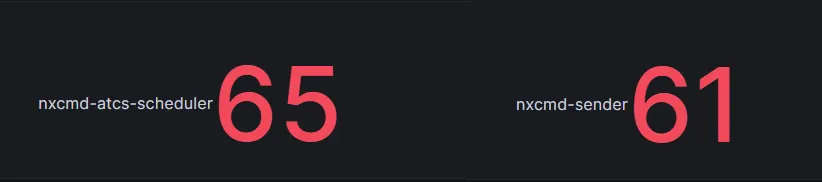
그림 19: 최대의 부하가 가해지는 상황에서 스케일 아웃이 진행된 후 대시보드에 표시된 파드 수
쿠버네티스의 서비스 파드가 부하를 감당할 수 있는 수준까지 스케일 아웃이 진행된 시점에, Redis의 KEYS 명령어를 호출하여 ATCS 메시지 등록 스트림에 속한 컨슈머들이 할당된 파티션 목록을 조회한 결과는 그림 20과 같습니다.
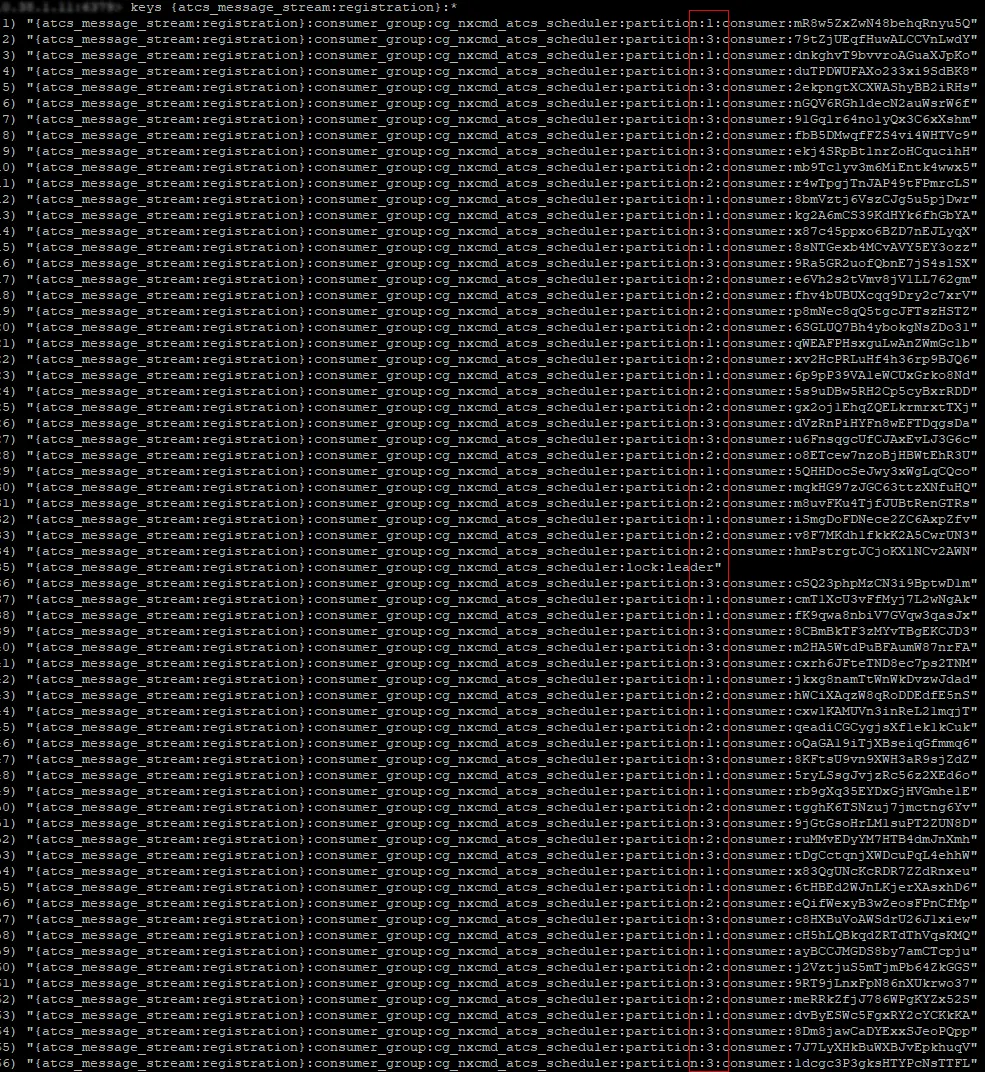
그림 20: 스케일 아웃 (scale out)이 완료된 후 컨슈머들이 파티션에 균일하게 할당된 모습
그림에서 표시된 결과를 기반으로 파티션에 할당된 팔로워 컨슈머들의 수는 다음 표와 같습니다.
Partition no. | # of follower consumers |
1 | 22 |
2 | 22 |
3 | 21 |
이는 팔로워 컨슈머들이 각 파티션에 균일하게 할당된 상태를 보여줍니다.
4. 오토스케일링 과정에서 파티션 할당 분포 - 스케일 인
부하가 종료되고 다시 스케일 인이 진행되면서 파드 수가 처음의 9대로 줄어들었을 때, ATCS 메시지 등록 스트림에 속한 파티션들의 목록을 조회한 결과는 그림 21과 같습니다.

그림 21. 스케일 인 (scale in)이 완료된 후 남아있는 컨슈머들이 파티션에 균일하게 할당된 모습
그림에서 표시된 결과를 기반으로 파티션에 할당된 팔로워 컨슈머들의 수는 다음 표와 같습니다.
Partition no. | # of follower consumers |
1 | 3 |
2 | 3 |
3 | 3 |
결과를 통해 팔로워 컨슈머들이 스케일 인 이후에도 여전히 각 파티션에 균일하게 할당된 것을 확인할 수 있습니다.
5. 컨슈머들의 리소스 사용률
그림 22는 컨슈머 역할인 ATCS 스케줄러의 CPU 및 메모리의 사용률 추이를 나타내고 있습니다.

그림 22. Redis Streams에서 컨슈머 역할의 파드들이 시간 경과에 따라 리소스를 균일하게 사용하는 모습
스케일 아웃으로 인해 파드의 수가 60대 넘게 늘어났음에도 모든 컨슈머들이 프로듀서로부터 등록된 스트림 메시지를 균일하게 가져와 처리하고 있음을 메트릭 차트를 통해 알 수 있습니다.
프로듀서 역할인 NXCommand 서버는 Redis SPAR 라이브러리와 무관하게 이미 부하를 균일하게 분산 처리하고 있었기 때문에 결과에 포함시키지 않았습니다.
나가며
이번 포스팅을 통해 Redis Cluster 환경에서 스트림의 확장성을 높이기 위해 스트림 파티셔닝 및 파티션 리밸런싱 기능을 제공하는 Redis SPAR (Stream Partition Automatic Rebalancer) 라이브러리에 대해 소개하였습니다.
Redis SPAR는 Redis Cluster의 모든 샤드에 스트림의 부하를 균일하게 분산시키기 위해 샤드마다 스트림 파티션을 생성하는데, 컨슈머들은 파티셔닝 기법을 통해 각 파티션에 균일하게 할당되어 메시지를 처리할 수 있습니다. 성능 테스트 결과, 각 샤드의 프라이머리 노드에서 균일한 양의 스트림 기반 명령어가 호출된 것을 확인하였으며, 오토스케일링 기법이 적용된 상황 속에서 스케일 아웃 및 스케일 인이 진행된 이후에도 각 파티션에 균일한 수의 컨슈머들이 할당된 것을 확인할 수 있었습니다.
앞으로도 ATCS와 관련된 연구에 대해 많은 기대 부탁드립니다. 긴 글 읽어주셔서 감사합니다.
Reference
 함께 읽으면 좋은 콘텐츠
함께 읽으면 좋은 콘텐츠 









 테크블로그 문의 gs_site_contents@nexon.co.kr
테크블로그 문의 gs_site_contents@nexon.co.kr