

들어가며
안녕하세요, 플랫폼본부(前 인텔리전스랩스) 개인화콘텐츠팀 유정현입니다.
저는 LLM 기반 AI Research Engineering 업무를 맡고 있으며, 빠르게 진화하는 기술을 실제 비즈니스에 효과적으로 접목하는 방법을 고민하고 있습니다.
이번 글에서는  FC 온라인에서 친구로 등록된 유저(더비 매치)에게 승리 확률을 높일 수 있도록 도와주는 전술 추천 주제를 다루었습니다.
FC 온라인에서 친구로 등록된 유저(더비 매치)에게 승리 확률을 높일 수 있도록 도와주는 전술 추천 주제를 다루었습니다.
FC 온라인에서 친구로 등록된 유저(더비 매치)에게 승리 확률을 높일 수 있도록 도와주는 전술 추천 주제를 다루었습니다.개인화 추천 기술에 지속적인 관심을 갖고 있으며, 앞으로도 유저분들께 더 재미있고 유용한 콘텐츠를 제공할 수 있도록 노력하겠습니다.
1. 전술 추천 시스템의 개발 배경
축구를 좋아하신다면, 2015-16 시즌 프리미어리그를 잊기 어려우실 겁니다. 우승 확률 5,000:1의 언더독으로 평가받던 레스터 시티가 결국 리그 우승을 차지한, 그야말로 드라마 같은 시즌이었죠. 2008-09 시즌의 바르셀로나 역시 마찬가지입니다. 펩 과르디올라 감독이 선보인 티키타카 전술은 유럽 챔피언 등극과 함께 전 세계 축구팬들에게 깊은 인상을 남겼습니다.
FC 온라인의 세계도 실제 축구와 크게 다르지 않습니다. 승패를 결정짓는 핵심 요소는 선수 능력치나 급여 같은 구단 가치뿐 아니라, 유저의 플레이 성향과 이를 뒷받침하는 전술 구성입니다. 예를 들어, 레알 마드리드의 ‘갈락티코’는 지단 감독 체제 아래 베일, 호날두, 벤제마로 구성된 BBC 라인을 통해 라 데시마를 달성했습니다.
하지만, 레스터 시티가 강팀들을 상대로 맞춤 전략으로 돌파구를 찾아낸 것처럼, FC 온라인에서도 개인화된 정밀 전술은 유저에게 새로운 승리의 가능성을 열어줍니다. 유저의 플레이 스타일을 분석하고, 유사한 성향의 다른 유저 데이터를 학습하여, 특정 더비 매치 상대에게 가장 높은 승률을 보장할 수 있는 단 하나의 전술을 추천하는 것. 그게 바로 이번 프로젝트의 핵심 목표입니다.
2. 추천 시스템에 LLM을 도입한 이유
사실 기존에도 FC 온라인 내에는 전술 추천 기능이 존재했습니다. 다만, 이는 동일한 포메이션을 사용하는 상위 랭커들의 전술을 일괄적으로 제시하는 방식이었기 때문에, 범용성은 확보할 수 있었지만 특정 상대를 공략하기 위한 ‘나만의 맞춤 전술’과는 거리가 있었습니다.
즉, 개별 유저의 플레이 스타일이나 상대방의 특성을 고려한 정교한 개인화 추천에는 한계가 분명했던 것이죠.

이미지 1: 기존 전술 추천 콘텐츠 지면
이러한 한계를 극복하고 보다 높은 수준의 개인화된 전술 추천을 제공하기 위해, 딥러닝 모델의 표현력을 극대화할 수 있는 접근으로 LLM(Large Language Model)을 도입하게 되었습니다.
LLM은 방대한 텍스트 데이터를 학습하며 문맥 이해와 의미 구분 능력이 탁월한데요, 이를 게임 데이터에 적용하면, 유저의 복잡한 플레이 기록 속에 숨어 있는 행동 패턴과 전술 성향을 더욱 정밀하게 포착할 수 있습니다.
이를 통해 보다 풍부한 컨텍스트가 반영된 고품질의 유저 임베딩과 전술 임베딩을 생성할 수 있을 것으로 기대했습니다.
3. 추천 시스템의 작동 원리
추천 방식은 넷플릭스나 유튜브의 알고리즘에서 널리 알려진 협업 필터링(Collaborative Filtering) 원리와 유사합니다.
즉, 나와 플레이 스타일이 유사한 유저들이 특정 상대를 상대로 높은 승률을 보인 전술이 있다면, 해당 전술은 나에게도 효과적일 가능성이 높다는 가정에서 출발합니다.
더비 유저(친구)에게 승리할 수 있는 최적의 전술을 추천하기 위해, 다음과 같은 데이터가 종합적으로 분석됩니다:
•
나와 내 친구(더비 상대) 간의 플레이 기록
•
내 친구와 다른 유저들 간의 경기 데이터

이미지 2: 친구에게 승리한 다른 유저들 중, 나와 플레이 유사도가 가장 높은 유저의 전술을 추천 받는 구조
매치ID | 구단주명 | 상대방 구단주명 | 플레이스타일 | 패스 점유율 | 드라이브 스루패스 횟수 | 드라이브 스루패스 성공률 | … | 사용한 전술ID | 승리 여부 |
52asldkfjf23… | 유저1(나) | 친구1 | 빈틈 공략 | 83% | 8 | 37% | … | 44115234 | 0 |
411lkj452sdf… | 유저1(나) | 친구1 | 빈틈 공략 | 90% | 5 | 39% | … | 4420543 | 0 |
… | … | … | … | … | … | … | … | … | … |
523sdf2111d… | 유저2(상대방) | 친구1 | 측면 공략 | 73% | 15 | 65% | … | 41238958 | 1 |
124sdfasdge… | 유저3(상대방) | 친구1 | 빈틈 공략 | 85% | 7 | 40% | … | 42310312 | 1 |
이렇게 다양한 관계와 맥락 속에서 수집된 방대한 경기 로그는 LLM을 통해 각 유저와 전술의 특성을 표현하는 임베딩(Embedding)으로 변환됩니다.
이 임베딩 벡터들은 추천 모델 학습의 핵심 재료로 활용되며, 유저 맞춤 전술을 정교하게 도출하는 기반이 됩니다.
4. LLM 기반 추천 모델의 개발 과정
LLM 기반 추천 모델의 전체 구조는 크게 Downstream과 Upstream의 2단계로 나뉩니다.
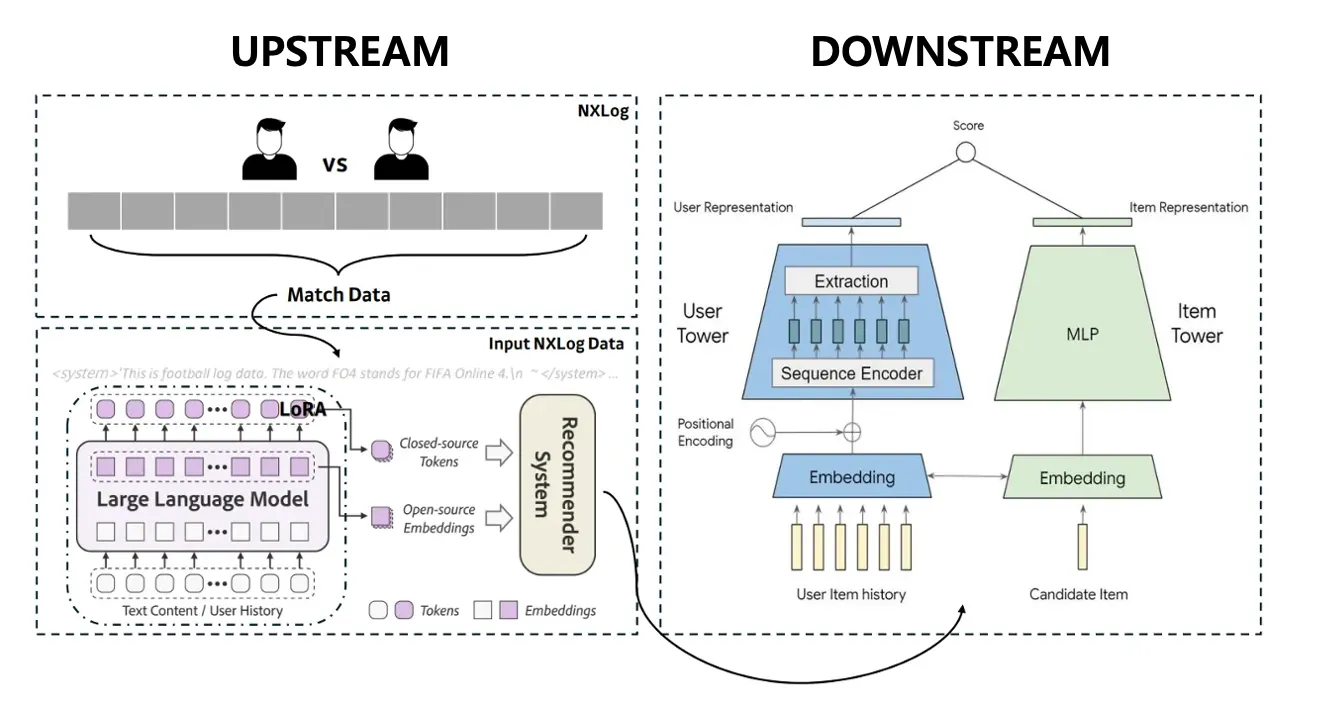
이미지 3: LLM 기반 더비 유저 전술 추천 모델의 구조
4-1. Uptream: 임베딩 생성
추천 모델의 성능은 입력 데이터의 질, 즉 임베딩의 품질에 크게 좌우됩니다.
이에 우리는 LLM의 강점을 활용해, 유저와 전술(아이템)의 특성을 보다 정교하게 이해하고 표현할 수 있는 임베딩을 생성하는 데 집중했습니다.
데이터 처리 및 LLM 활용
방대한 FC 온라인 경기 데이터를 LLM이 처리할 수 있도록 few-shot 프롬프트 형식으로 변환해 입력했습니다. 이 과정에서 LLM은 단순한 수치 정보(예: 패스 성공률, 슈팅 수)뿐만 아니라 전술 코드, 포메이션 변경 이력, 팀 컬러 등 다양한 요소를 종합적으로 고려해 각 경기의 맥락을 파악합니다. 그리고 이를 기반으로 고차원 임베딩(5,120차원 벡터) 을 생성합니다.
아래는 전처리된 FC 온라인 데이터를 기반으로 few-shot 프롬프트를 구성하고, LLM이 일관된 방식으로 임베딩을 생성하도록 유도한 사례입니다.
# 프롬프트 예시
Input user contexts[1]: ->
"""
<system>'As a football match analyst, understand the following terms:
feature1 is blah blah blah..
feature2 is blah blah blah..
...
You must print it out like the jon file below. And, briefly, proceed with a summary of these data.
{
"userID": user_id,
"teamcolorname": teamcolorname,
"formation": 000,
"feature2:: 000,
...
"Summary": "summary of these data."
}
</system>
<Data>
실제 FC 온라인 매치 데이터 INPUT
</Data>
"""
Markdown
복사
few-shot으로 입력한 프롬프트 예시
이때, Instructor Prompt에 포함된 JSON 형식을 엄격히 따르도록 하기 위해 temperature, top_p 등의 파라미터를 조정하며 출력 결과를 검토했습니다. 이렇게 데이터를 입력했을 때, 아래와 같이 디코더 단계에서 원하는 형식으로 잘 생성된 결과를 확인할 수 있었습니다.
output[1]:
<think>
...
</think>
```json
{
"userID": 12345,
"teamcolorname": "PSV",
"formation": "4-1-2-3",
"feature2": 12423502,
...
"Summary": "The match was characterized by defensive caution, with both teams maintaining strong structures. PSV attempted to maintain possession but struggled to convert it into goals. The game was eventful in terms of defensive actions but lacked clear scoring chances, resulting in a low-scoring draw or loss for PSV. Further analysis would benefit from understanding specific tactical codes and advanced metrics in FIFA Online 4 to gain deeper insights into gameplay dynamics."
}
```
Now, Data is ...
Markdown
복사
LLM 모델의 디코딩 성능을 확인한 뒤, 전처리를 마친 데이터를 기반으로 최종 레이어에서 추출한 벡터를 임베딩 차원으로 활용했습니다.
임베딩 검증
이렇게 생성된 임베딩 벡터를 분석한 결과, 일부 인덱스 구간에서 매우 큰 절댓값을 가지는 등 뚜렷한 값의 분포 특성이 관찰되었습니다. 이는 LLM이 경기 데이터 내 특정 패턴이나 주요 특징을 강하게 인코딩하고 있음을 의미합니다. 실제로, Summary 영역이나 공격 전술 훈련 여부, 포메이션 변경과 관련된 특성 인덱스에서 의미 있는 차이가 나타나는 것을 확인할 수 있었습니다.
Input user contexts[1] - Input user contexts[2]:
tensor([ 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, -8,
-1, 0, 0, 0, 0, 17452, -130, -33748,
-599, 96920, 33785, 9588, 101892, 30421, 3863, 26589,
3491, -3776, -27605, -3286, 432, -7, -30002, 27529,
-47137, -108609, -45593, -52735, -3963, 30364, 2424, 37,
1439, 6, 208, 3, 0, 0, 0, -2,
-22500, -1, 22477, -4063, -6931, -11860, -92392, 14189,
99333, -8508, 9, 5155, 0, 0, 0, 0,
0, 0, 0, 0, 0, 5046, -22496, 41,
3789, -32, 11757, -15891, -92392, 14189, 99333, 1243,
-1016, -1211, -4065, 2288, 0, 0, 0, 0,
0, 0, 0, 0, 5046, -22496, 41, 22468,
-4063, -6922, -11860, -92392, 14189, 99333, -8508, 9,
5155, 0, 0, 0, 0, 0, 0, 0,
0, 0, 5046, -16495, -44226, 16486, 44066, 10,
-997, -62999, 910, 62989, 87, 5, 158, -3,
0, 2, 0, -5, 0, 5, 0, -4,
0, 3, 0, -2, 0, -3, 0, 0,
50, 3, 0, 0, 0, 3, 0, -2,
0, 0, 0, 0, 0, -1, 0, 2512,
0, 0, 0, 0, 0, -3, 0, 3797,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 2, 0,
118, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 2, 0, 6076, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 3797, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 110, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 110, 0, 0, 0, 0, 0, 0,
0, 0, 0, 110, 0, 0, 0, 0,
0, 0, 0, 0, 118, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, -2, 0,
2170, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 118, 0, 0,
0, 0, 0, 0, 0, 2, 0, 2170,
0, 0, 0, 0, 0, 0, 0, 1,
0, 2512, 0, 0, 0, 0, 0, 0,
0, 2, 0, 2170, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 118, 0, 0, 0, 0, 0,
0, -1216, 0, 4136, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, -3,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, -4, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
110, 0, 0, 0, 0, 0, 0, 0,
6536, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 2512, 0, 0, 0, 0,
0, 0, 0, 0, 0, 110, 0, 0,
0, 0, 0, 0, 1, 0, 2170, 0,
0, 0, 0, 0, 0, -1, 0, 6076,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1705, 0, 0, 0, 0, 0,
0, 0, 0, 0, 6076, 0, 0, 0,
0, 0, 0, 0, -1, 0, 2170, 0,
0, 0, 0, 0, 626, 0, 118, 0,
0, 0, 0, 0, 0, 3648, 0, 4136,
0, 0, 0, 0, 0, 988, 0, 2,
0, 0, 0, 0, 0, 0, 3, 0,
1705, 0, 0, 0, 0, 0, 0, -697,
0, 1705, 0, 0, 0, 0, 0, 0,
0, 0, -331, 0, 2170, 0, 0, 0,
0, 0, 0, 0, -783, 0, 1705, 0,
0, 0, 0, 0, 0, 0, -444, 0,
118, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, -381, 0,
1705, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, -726, 0, 4136, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, ...])
Markdown
복사
첫 번째 경기 데이터와 두 번째 경기 데이터에서 생성된 토큰 임베딩을 비교한 결과, 일부 구간에서 뚜렷한 차이가 확인되었습니다. 이는 LLM 모델이 각 경기의 문맥이나 특성에 따라 상이한 방식으로 반응하고 정보를 인코딩했음을 시사합니다.
추론 최적화: 양자화와 GPU 분산 처리
앞서 LLM 모델의 기본적인 추론 성능을 확인한 만큼, 이제 해당 모델을 임베딩 생성기(embedding generator)로 활용하고자 합니다.
하지만 LLM 모델을 실제 업무에 적용하기 위해서는 상당한 수준의 GPU 메모리 자원이 요구됩니다. 따라서 제한된 자원 환경에서 효율적으로 모델을 운영하기 위해서는 최적화 기법의 적용이 필수적입니다.
이번 작업에서는 대표적인 최적화 기법 중 하나인 양자화(Quantization)를 도입했습니다. 그렇다면 왜 양자화가 필요한지 그 이유를 간단히 설명드리겠습니다.
예를 들어, RTX 6000 Ada 48GiB GPU 1개 슬롯이 있다고 가정해보겠습니다. 이때 일반적으로 8B, 14B, 32B 규모의 LLM을 각각 float32, float16, int8, int4 형식으로 실행할 경우, 모델 크기와 정밀도에 따른 메모리 사용량 차이가 아래와 같이 발생합니다.
모델 크기 | 비트폭 | 메모리 (GiB) | 절감율 | 48GiB 가능 여부 |
8 B | float32 | 29.8 GiB | – | O |
float16 | 14.9 GiB | 50 % | O | |
int8 | 7.45 GiB | 75 % | O | |
int4 | 3.73 GiB | 87.5 % | O | |
14 B | float32 | 52.2 GiB | – | X (초과: 52.2 GiB) |
float16 | 26.1 GiB | 50 % | O | |
int8 | 13.0 GiB | 75 % | O | |
int4 | 6.52 GiB | 87.5 % | O | |
32 B | float32 | 119.2 GiB | – | X (초과: 119.2 GiB) |
float16 | 59.6 GiB | 50 % | X (초과: 59.6 GiB) | |
int8 | 29.8 GiB | 75 % | O | |
int4 | 14.9 GiB | 87.5 % | O |
RTX 6000 Ada GPU는 48GiB의 메모리를 탑재하고 있지만, float32 포맷을 그대로 사용할 경우 추론 성능이 준수한 32B 모델은 물론, 상대적으로 가벼운 14B 모델조차 OOM(Out Of Memory) 오류가 발생할 수 있습니다.
이러한 문제를 해결하기 위해 양자화(Quantization) 기법을 적용했습니다. 양자화란 신경망 모델의 가중치(weight)와 활성값(activation)을 부동소수점(Floating-point) 대신, 정수(Integer) 혹은 고정소수점(Fixed-point) 숫자 형식으로 변환해 더 적은 비트 수로 표현하는 기술입니다.
이러한 방식은 32B 이상의 초대형 모델도 단일 GPU 환경에서 실행 가능하게 하며, 특히 메모리와 계산 자원에 제약이 있는 상황에서도 모델 성능 저하 없이 효율적인 추론 환경을 제공합니다.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map={"": local_rank},
trust_remote_code=True,
...
)
Python
복사
저는 위 코드에서 Huggingface의 BitsAndBytesConfig 라이브러리를 활용하여 양자화를 적용하였으며, 각 파라미터가 실제로 어떤 방식으로 작동하는지 간단히 설명드리겠습니다.
•
load_in_4bit=True: 모델 가중치를 4-bit 정밀도로 불러옵니다. 이를 통해 메모리 사용량을 획기적으로 줄일 수 있습니다.
•
bnb_4bit_quant_type="nf4": 양자화 유형으로 NF4(NormalFloat-4) 를 선택했습니다. 이는 QLoRA 논문에서 제안된 방식으로, 가중치 분포의 통계적 특성(평균, 분산 등)에 맞춰 비균등(non-uniform) 하게 16개 양자화 레벨을 배정합니다. FP4 대비 연산 속도에서 유리하고, 균등 분할 방식보다 표현 오차를 줄일 수 있는 장점이 있습니다.
•
bnb_4bit_compute_dtype=torch.bfloat16: 양자화된 int4끼리의 연산은 bfloat16 정밀도로 수행합니다. 이는 float32 대비 메모리 사용량과 대역폭을 절반 이하로 줄이면서도 계산 정확도를 일정 수준 유지할 수 있습니다.
•
bnb_4bit_use_double_quant=True: 이중 양자화(Double Quantization) 를 적용합니다. 이 기법은 마치 사진을 압축할 때 해상도를 한 번에 크게 줄이기보다는 두 단계로 나눠서 줄여 손실을 최소화하는 방식과 유사합니다. 32bit 가중치를 바로 4bit로 변환하는 대신, 중간 단계를 거쳐 정밀도를 보다 안정적으로 보존할 수 있게 해줍니다.
이 설정을 적용하면, 모델은 float32 형태의 원본 가중치를 불러온 뒤, 내부적으로 scale과 zero point를 계산하고, 이를 기반으로 NF4 스킴에 따라 int4로 변환하여 packed format으로 저장합니다. 이렇게 함으로써 메모리 효율성과 계산 성능을 확보하는 동시에, LLM의 표현력을 최대한 유지할 수 있게 됩니다.

이미지 4: NVIDIA에서 발표한 양자화 개념. 부동 소수점을 int8로 양자화하는 과정입니다.
이후 추론 단계에서는, int4로 압축된 가중치가 GPU에 적재된 상태에서 입력 데이터가 들어오면 가중치를 unpack하고 dequantize하여 bfloat16 형식으로 변환하게 됩니다. 이 과정을 통해 int4 수준의 메모리 절감 효과는 유지하면서도, 연산 정밀도는 bfloat16 수준으로 확보할 수 있습니다.
양자화 설정이 완료되면, 다음 단계는 대규모 임베딩 추출을 위한 분산 추론 작업입니다. 이 단계에서는 PyTorch의 DistributedDataParallel(DDP) 기능을 활용하여 다수의 GPU에서 병렬로 데이터를 처리하며, 효율적으로 고차원 임베딩을 생성하게 됩니다.
# GPU 분산처리 기본 실행 (4개의 GPU를 모두 사용할 경우)
torchrun --nproc_per_node=4 llm_embedding_extraction.py
Python
복사
DDP는 여러 개의 GPU를 하나의 병렬 처리 장치처럼 동작하게 만들어, 대규모 연산을 효과적으로 분산시킬 수 있는 기술입니다. PyTorch에서는 torch.nn.parallel.DistributedDataParallel() 모듈을 통해 구현할 수 있으며, 본 프로젝트에서는 다음과 같은 방식으로 DDP를 활용했습니다.
•
Process Group: 각 GPU마다 별도의 프로세스를 띄운 후, torch.distributed.init_process_group()을 통해 하나의 그룹으로 묶습니다.
•
Rank & World Size: 전체 프로세스의 수(world_size)와 각 프로세스의 고유 식별자(rank)를 기반으로 통신을 조율합니다.
•
Barrier: 모든 프로세스가 동일한 지점까지 도달할 때까지 dist.barrier()를 사용해 동기화합니다.
이처럼 DDP는 각 GPU에 동일한 모델과 데이터를 복사하여 추론을 병렬 수행할 수 있도록 해주며, 학습 시에는 각 GPU의 gradient를 실시간으로 동기화하는 역할도 수행합니다.
GPU 간 통신을 위한 백엔드로는 NCCL(NVIDIA Collective Communications Library)을 사용했습니다. NCCL은 NVIDIA GPU 환경에 최적화되어 있을 뿐 아니라, GPU 간 직접 통신 시 발생할 수 있는 대역폭 병목을 최소화할 수 있어 본 프로젝트에 적합한 선택이었습니다.
[Rank 0] Extracting embeddings: 97%|██████████████████████████████████████████████████████████████████ | 81337/83758 [00:00<00:00, 12.42it/s]2025-04-07 19:55:25,849 - __main__ - INFO - Embedding stats: mean=-0.0000, std=0.5273, avg_norm=16.0000
[Rank 0] Extracting embeddings: 97%|██████████████████████████████████████████████████████████████████ | 81365/83758 [00:00<00:00, 12.42it/s]2025-04-07 19:55:37,417 - __main__ - INFO - Rank 3: Saved 1340123 item embeddings to ./weights/item_embedding_rank3.pt
[Rank 0] Extracting embeddings: 100%|████████████████████████████████████████████████████████████████████| 83758/83758 [00:00<00:00, 12.41it/s]
2025-04-07 20:12:17,711 - __main__ - INFO - Embedding stats: mean=0.0001, std=0.4746, avg_norm=16.0000
2025-04-07 20:12:29,675 - __main__ - INFO - Rank 0: Saved 1340123 item embeddings to ./weights/item_embedding_rank0.pt
2025-04-07 20:35:24,064 - __main__ - INFO - Embedding stats: mean=-0.0001, std=0.5117, avg_norm=16.0000
2025-04-07 20:35:35,354 - __main__ - INFO - Rank 1: Saved 1340123 item embeddings to ./weights/item_embedding_rank1.pt
2025-04-07 20:44:01,444 - __main__ - INFO - Embedding stats: mean=-0.0002, std=0.4941, avg_norm=16.0000
2025-04-07 20:44:13,827 - __main__ - INFO - Rank 2: Saved 1340123 item embeddings to ./weights/item_embedding_rank2.pt
Markdown
복사
위 로그는 아이템 임베딩 추론 과정에서 출력된 로그입니다. 추론 진행 상황은 주로 Rank 0에서 모니터링하였으며, 각 Rank에서 생성된 임베딩에 대해서는 평균, 분산 등의 통계값을 기준으로 품질을 확인했습니다.
일반적으로 임베딩의 분산 값이 지나치게 낮을 경우 표현력이 부족하다고 판단할 수 있으며, 반대로 분산이 지나치게 높을 경우 수치적 불안정성이 발생할 가능성이 있습니다. 분산 값이 0.5 내외로 형성된다면, 일반적인 LLM 임베딩 수준으로 안정적으로 작동하고 있다고 해석할 수 있습니다.
Downstream에 사용하기 위한 임베딩 경량화
양자화와 병렬 분산 처리를 통해 고품질 임베딩을 생성할 준비는 모두 마쳤습니다. 그러나 임베딩 생성은 어디까지나 Upstream 단계일 뿐이며, 실제 추천은 Downstream 단계에서 이뤄집니다. 문제는 1개의 임베딩이 5,120차원에 달하기 때문에, 이대로는 계산 비용이 매우 높다는 점입니다.
이를 해결하기 위해, 생성된 (n,5120) 임베딩을 Downstream에서 효율적으로 활용할 수 있도록 경량화를 수행했습니다. 경량화 방식으로는 두 가지 접근을 시도했으며, AutoEncoder(AE)와 단순 nn.Linear 레이어 기반 차원 축소의 성능을 비교했습니다.
실험 결과, AE를 사용했을 때가 nn.Linear 대비 Validation Loss의 수렴 속도가 더 빠르고, 추천 정확도 지표 중 하나인 AUC에서도 더 우수한 성능을 보였습니다. 따라서 최종적으로는 AE를 통해 256차원으로 축소한 임베딩을 사용하며, 이 임베딩과 학습된 가중치는 AWS S3에 저장됩니다.
AutoEncoderProjectionModule(
(norm): LayerNorm((5120,), eps=1e-05, elementwise_affine=True)
(encoder): Sequential(
(0): Linear(in_features=5120, out_features=2048, bias=False)
(1): GELU(approximate='tahn')
(2): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(3): Linear(in_features=2048, out_features=256, bias=False)
)
(decoder): Sequential(
(0): Linear(in_features=256, out_features=2048, bias=False)
(1): GELU(approximate='tahn')
(2): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(3): Linear(in_features=2048, out_features=5120, bias=False)
)
)
Python
복사
LLM 모델로 추출된 임베딩을 위의 구조를 가진 모델로 차원을 축소시킵니다.

이미지 5: AutoEncoder(AE)와 nn.Linear 기반 임베딩 결과 비교
4-2. Downstream: Two-Tower 추천 모델
잘 정제된 유저 임베딩과 전술 임베딩이 준비되면, 본격적으로 추천 모델 학습 단계로 넘어갑니다. 이 단계에서는 Two-Tower 모델 구조를 채택했습니다.
이름에서 알 수 있듯, Two-Tower 모델은 두 개의 독립된 신경망 타워—하나는 유저 정보를 처리하는 유저 타워, 다른 하나는 전술 정보를 처리하는 아이템 타워—로 구성됩니다. 주요 구성 요소는 다음과 같습니다.
•
user_embedding 및 item_embedding: 앞서 LLM과 AE를 통해 생성된 256차원의 유저 및 전술 임베딩을 입력으로 사용합니다. 각 임베딩은 13억 개의 파라미터를 갖고 있으며, 학습 과정에서는 고정된 상태로 사용됩니다.
•
user_tower 및 item_tower: 각 타워는 약 72만 개의 학습 가능한 파라미터를 가진 순차 신경망으로 구성되어 있으며, 입력 임베딩에서 고차원 특징을 추출합니다. 이 부분은 학습 과정에서 계속 업데이트됩니다.
•
유사도 계산: 각 타워를 통과한 유저 벡터와 전술 벡터 간 **내적(dot product)**을 계산해 유사도 점수를 산출합니다. 점수가 높을수록, 해당 유저에게 그 전술이 효과적일 가능성이 높다고 판단합니다.
•
Loss: 학습 손실 함수로는 Pairwise Ranking Loss, 그 중에서도 **Bayesian Personalized Ranking Loss (BPR)**을 사용했습니다. 이 방식은 유저가 실제로 사용했고 승리한 전술(Positive)과, 그렇지 않은 전술(Negative) 간의 상대적인 선호도 차이를 학습합니다.
이 단계의 핵심은 바로 Loss 함수의 설계에 있습니다. 모델은 Positive 전술이 Negative 전술보다 더 높은 추천 점수를 받도록 학습됩니다. 이를 통해 단순히 ‘좋아할 만한’ 전술을 추천하는 수준을 넘어서, 상황에 따라 효과적인 전술을 구분해낼 수 있게 됩니다.
모델 손실 함수 설계
그렇다면 이 모델의 손실 함수를 어떻게 설계했는지 조금 더 자세히 살펴보겠습니다.
우선, BPR을 선택한 이유부터 설명드리겠습니다. 추천 시스템에 관심이 있으신 분들이라면 RecSyS(2024)를 잘 아실 텐데요. 이 학회에서 발표된 “Revisiting BPR: A Replicability Study of a Common Recommender System Baseline” 논문은 BPR의 재현 가능성과 일관성, 성능을 분석한 연구입니다.
이 논문에서는 BPR이 다양한 모델 구조에 유연하게 적용될 수 있고, 특히 협업 필터링 기반 모델에 매우 적합하다고 평가합니다. 실제로 논문의 인용 수도 꾸준히 증가하고 있어, BPR의 지속적인 영향력을 보여줍니다.

이미지 6: BPR 논문의 연도별 인용 횟수 변화
또한, 손실 함수로 BPR을 선택한 이유는 커스터마이징이 용이하다는 점에서도 찾을 수 있습니다.
이때 일반적인 Negative Sampling 대신, Hard Negative Sampling 기법을 함께 적용했습니다. Hard Negative는 겉보기에는 유사하지만 실제로는 다른 카테고리에 속하는 샘플을 의미합니다.
추천 시스템에서는 사용자가 실제로는 선호하지 않지만, 모델이 높은 점수를 줄 가능성이 있는 아이템을 뜻합니다. 예를 들어, FC 온라인에서 사용자가 사용한 적은 없지만, 임베딩 공간상 선호 전술과 매우 유사한 전술이 이에 해당합니다. 모델이 구분하기 어려운 이 경계선 사례들을 학습함으로써, 임베딩 공간에서 더 많은 학습 효과를 얻을 수 있습니다.
다만, Hard Negative가 지나치게 많아지면, 실제로는 선호할 수도 있는 아이템이 false negative로 처리되어 모델 성능에 부정적인 영향을 줄 수 있습니다. 따라서 Negative와 Hard Negative를 8:2 비율로 조합해 모델이 균형 있게 학습되도록 설계했습니다.

이미지 7: Hard Negative Sampling과 일반 Negative Sampling의 비교
# Hard Negative Sampling
if neg_mask.sum() > num_neg * pos_mask.sum():
neg_scores_all = scores[neg_mask]
hard_ratio = 0.2
num_hard_samples = int(min(num_neg * pos_mask.sum(), len(neg_scores_all)) * hard_ratio)
_, hard_neg_indices = torch.topk(neg_scores_all, k=num_hard_samples)
hard_neg_scores = neg_scores_all[hard_neg_indices]
...
neg_scores = torch.cat([hard_neg_scores, random_neg_scores], dim=0)
# Margin Loss (커스터마이징 목적의 Class형태로 구현)
class BPRLoss(nn.Module):
def forward(self, pos_scores, neg_scores):
return -torch.log(torch.sigmoid(pos_scores - neg_scores - margin) + 1e-8).mean()
Python
복사
Hard Negative와 Negative Sampling 외에도 Margin이라는 개념을 함께 도입해, Positive와 Negative 간의 유사도 차이가 일정 임계값 이상 나도록 학습을 유도했습니다. 이 Margin은 모델이 더 어려운 샘플을 잘 구분할 수 있도록 도와주는 기준선 역할을 합니다.
이러한 설계를 통해 완성된 추천 모델은 다음과 같은 구조를 갖추고 있으며, AUC 기준 평균 0.814의 성능을 기록했습니다.
| Name | Type | Params | Mode
---------------------------------------------------------------
0 | user_embedding | PretrainedEmbedding | 1.3 B | train
1 | item_embedding | PretrainedEmbedding | 1.3 B | train
2 | user_tower | Sequential | 724 K | train
3 | item_tower | Sequential | 724 K | train
4 | loss_fn | BPRLoss | 0 | train
---------------------------------------------------------------
1.4 M Trainable params
2.7 B Non-trainable params
2.7 B Total params
10,794.813 Total estimated model params size (MB)
21 Modules in train mode
0 Modules in eval mode
Markdown
복사
100%|██████████| 272/272 [00:06<00:00, 40.88it/s, v_num=3, val_auc=0.814, val_hit_rate_3=0.731]
Python
복사
5. 추천 모델의 비즈니스 성과 측정
지금까지 모델 설계와 학습 과정을 살펴봤습니다. 완성된 추천 모델은 FC 온라인의 My Pitch 지면을 통해 실제 유저들에게 제공되었으며, 아래와 같은 방식으로 성과를 측정했습니다.

이미지 8: FC 온라인의 My Pitch 지면에 적용된 추천 모델
먼저, 더비 매치에서 승률이 50% 미만인 유저를 대상으로 추천 메시지를 노출했고, 실험 기간은 총 2주였습니다. 이 기간 동안 Staggered Difference-in-Differences (Staggered DiD) 분석 기법을 적용해 유의미한 효과를 측정했습니다.

이미지 9: Staggered DiD 분석 결과 시각화
그 결과:
•
추천 메시지를 클릭한 유저는 클릭하지 않은 유저에 비해 평균 96분 더 오래 플레이했습니다.
•
전술을 실제로 변경한 유저의 승률은 평균 13%p 증가했습니다.
•
반면, 아무런 행동을 하지 않은 유저는 평균 2%p의 승률 감소를 보였습니다.
이를 종합해보면, 추천 메시지를 활용한 Lift는 약 +15% 수준으로 추정됩니다. 물론 모든 유저에게 동일한 효과가 나타나는 것은 아니지만, 전술 추천 기능을 적극적으로 활용할 경우 긍정적인 결과를 기대해볼 수 있습니다.

이미지 10: 왼쪽은 메세지를 클릭하고 전술을 변경한 그룹의 패배율의 변화량, 오른쪽은 반응하지 않은 유저의 패배율 변화량
6. 나가며
지금까지 FC 온라인 더비 전술 추천 시스템의 개발 과정과 실제 적용 결과를 살펴보았습니다. 현재는 Weekly Batch 형태로 데이터 수집부터 모델 학습, 배포까지 이뤄지고 있지만, 앞으로는 vLLM을 활용한 실시간 추천 시스템 구축을 목표로 개발을 진행 중입니다.
LLM은 그동안 텍스트 생성이나 번역 등 특정 영역에 국한되었지만, 이제는 복잡한 맥락을 이해하고 구조화된 데이터를 해석하는 능력까지 확보했습니다. 이번 프로젝트에서도 LLM은 게임 로그라는 특수한 도메인에서 뛰어난 패턴 인식과 추론 능력을 보여주었습니다.
앞으로도 더 강력해질 LLM 기술과 함께, 게임과 AI의 결합을 통해 더욱 흥미로운 콘텐츠를 선보일 수 있도록 노력하겠습니다.
Reference
 함께 읽으면 좋은 콘텐츠
함께 읽으면 좋은 콘텐츠 








 테크블로그 문의 gs_site_contents@nexon.co.kr
테크블로그 문의 gs_site_contents@nexon.co.kr