

Table of contents
들어가며
안녕하세요. 이번 포스트에서는 AI 보이스를 생성할 수 있는 Nexon Voice Creator에 대해 소개 드리고자 합니다. Nexon Voice Creator를 어떤 목적으로 개발하게 되었고, 어떻게 개발했는지 말씀드리겠습니다.
1. Nexon Voice Creator 개발 배경
TTS 기술 기반의 AI 보이스는 유튜브 콘텐츠, 오디오북 등 다양한 콘텐츠 제작에 활용되고 있습니다. 넥슨에서는 인게임과 마케팅 활동에 AI 보이스를 활용함으로써, 유저 경험을 개선하고 음성 제작에 투입되는 리소스를 절감하고자 합니다. 이를 위해 TTS 기술로 AI 보이스를 생성하는 Nexon Voice Creator를 개발하게 되었습니다. 첫 번째 챕터에서는 TTS 기술에 대해 소개 드리겠습니다.
TTS(Text-to-Speech)란?
Voice Creator TTS 모델 구조에 대하여 설명 드리기 앞서, TTS(Text-to-Speech)라는 Task에 대해서 간단히 설명 드리겠습니다. TTS(Text-to-Speech)는 말 그대로 텍스트를 인풋으로 넣어주면 음성, 목소리를 생성해내는 Task를 뜻합니다.
일반적인 TTS 모델 구조는 아래의 그림처럼 Acoustic model과 Vocoder model로 나뉘어, 입력된 텍스트에 대한 음성을 생성하게 됩니다.

Acoustic Model
Text를 Input으로 받아 Mel-Spectrogram(소리의 파형을 나타내는 Feature)을 생성합니다.
Vocoder Model
Mel-Spectrogram을 입력으로 받아 실제로 들을 수 있는 Audio를 생성합니다.
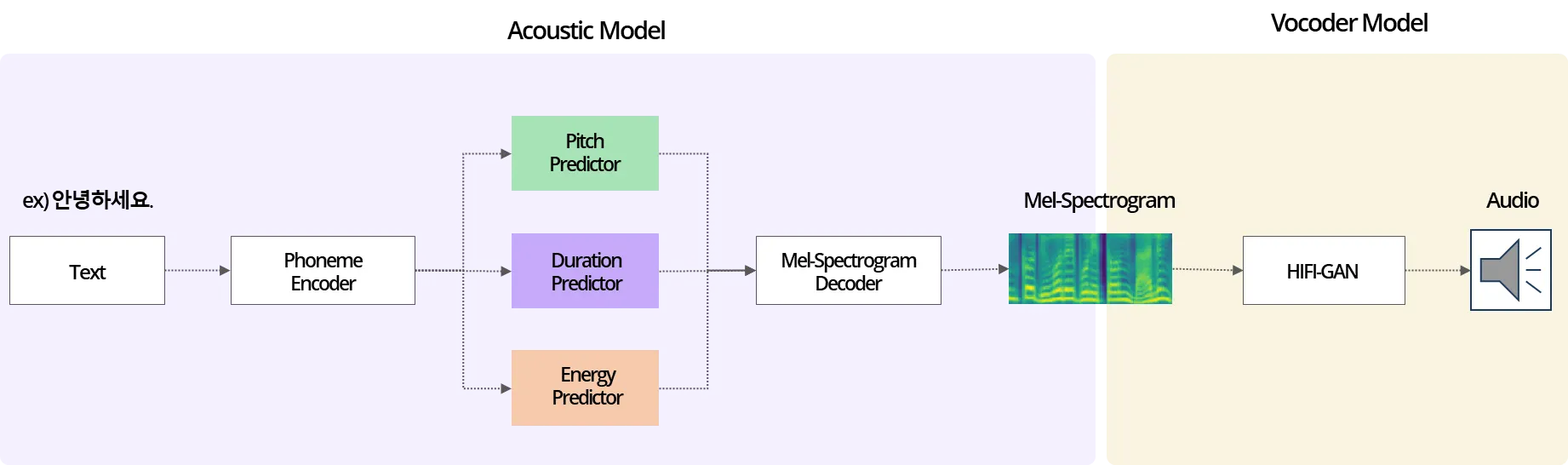
그림 1: 일반적인 TTS 음성 합성 과정
2. Voice Creator TTS 모델 개발 과정
2-1. 초기 TTS 모델 구조
먼저 아래 첨부된 그림은 Voice Creator 개발을 위해 시도했던 초기 Model 구조입니다. 해당 그림을 보면 텍스트를 인풋으로 받아 음성을 생성하는 TTS 모델의 플로우를 비교적 쉽게 이해할 수 있습니다. 우선 음성을 생성하기 위해서는 대표적으로 Energy / Pitch / Duration과 같은 음성의 3대 구성 요소가 필요합니다. 여기서 Energy / Pitch / Duration이 각각 의미하는 바는 음성의 볼륨 / 음성의 높낮이 / 음성의 길이입니다.
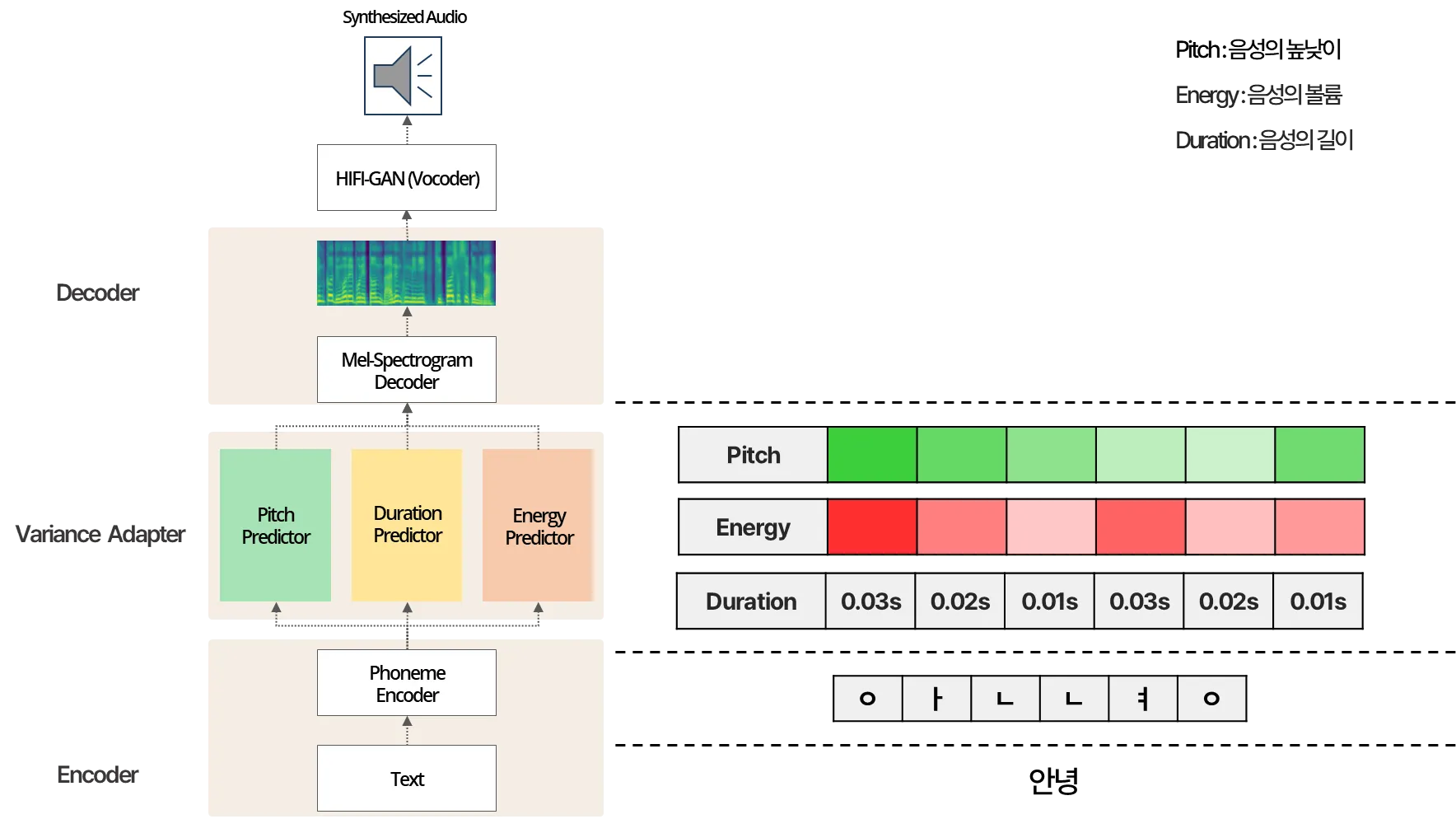
그림 2: 기존 TTS 모델 구조
TTS에서 일반적인 음성 합성 프로세스는 위 그림을 예로 설명 드리겠습니다. "안녕"이라는 텍스트가 자모로 분리되고, 각 자모에 해당하는 Energy / Pitch / Duration이 Variance Adaptor 모듈을 통해 예측됩니다. 이후, Variance Adaptor에서 처리된 정보는 Decoder에 입력되어 Mel-Spectrogram을 생성합니다. 마지막으로 생성된 Mel-Spectrogram은 Vocoder 모델에 입력되어 음성이 생성됩니다.
하지만, 이렇게 단순한 구조로는 게임에 어울리는 생동감 있고 다이내믹한 음성을 발화하는 데 한계가 존재했습니다. 이에, 게임 캐릭터의 음색과 스타일 등의 특성을 살릴 수 있는 모델 구조를 고민하게 되었고, StyleSpeech[1] 모델 구조를 활용하게 되었습니다.
2-2. Voice Creator TTS 모델 구조
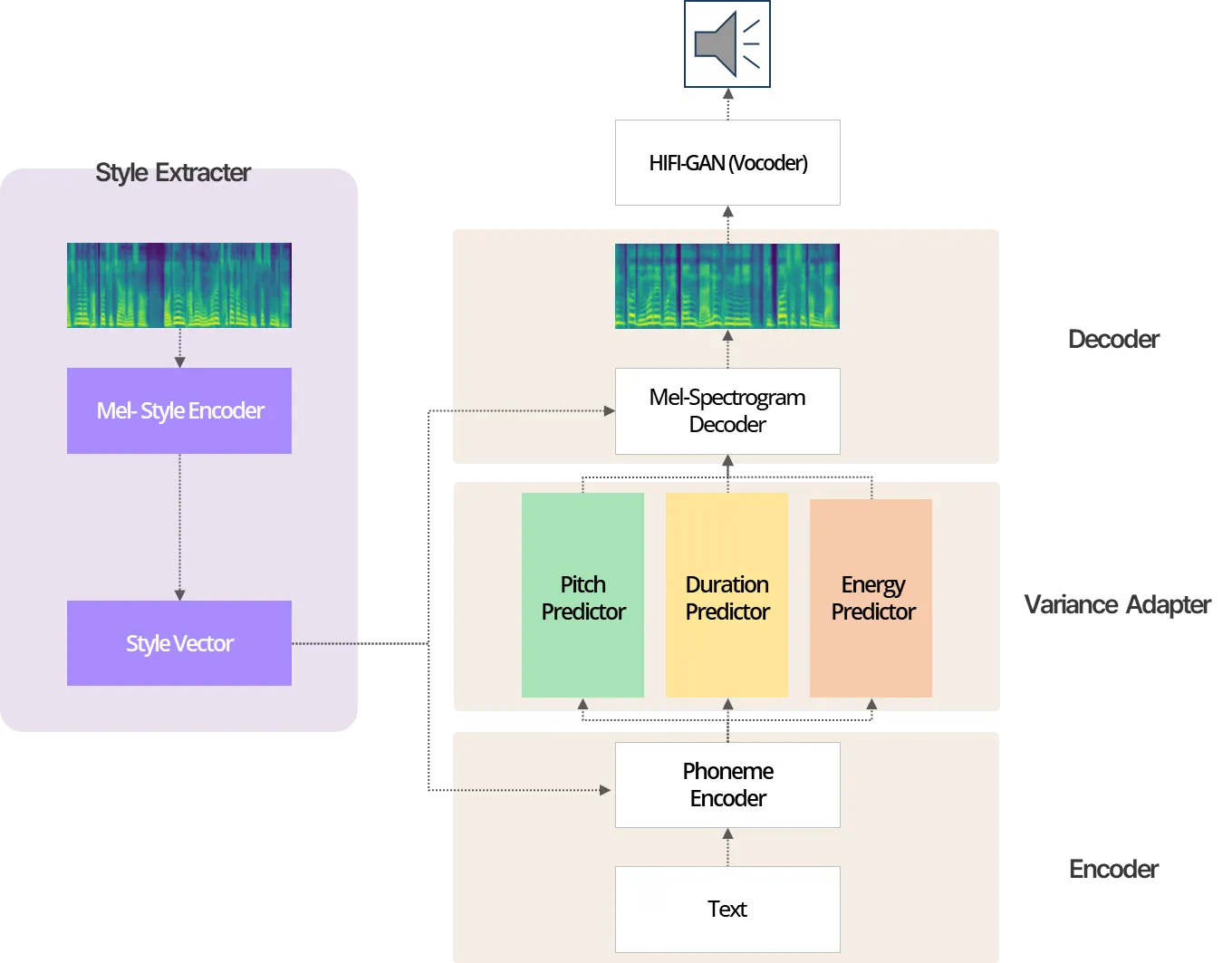
그림 3: Voice Creator 모델 구조
위 그림은 Voice Creator 내부의 Acoustic Model 스키마이며, StyleSpeech 모델이 뼈대를 이루고 있습니다. 앞서 설명 드렸던 기존 Acoustic Model 구조와 다르게 여러 모듈이 추가되어있는 것을 볼 수 있습니다. 왼쪽 상단의 Style Extractor는 Reference Audio를 입력받아 해당 음성 Style에 대표되는 특징들을 추출할 수 있어 음성 복제가 가능하도록 만들어 줍니다. 이를 통해 게임 내 다양한 상황에 활용하기 적절한, 특색 있는 목소리를 발화할 수 있게 되었습니다.
자연스러운 발화를 위해 기존 StyleSpeech[1] 모델 구조를 변경해 사용했습니다. 기존 StyleSpeech[1]에서 사용하는 alignment 방식은 Montreal Forced Aligner(MFA)라는 외부 툴을 이용해 사전에 음성과 텍스트 간의 alignment 결과를 미리 추출하게 되고, 이를 정답으로 생각하여 학습을 진행하게 됩니다. 하지만 만약 alignment 결과에 오류가 있다면 모델이 잘못된 정답을 가지고 학습되어, 최종적인 성능이 외부 툴 결과에 의존하게 되는 단점이 존재했습니다. Acoustic Model 내에 alignment를 자동화할 수 있는 모듈을 추가하여 외부 툴 성능에 의존하지 않고 안정적인 성능의 모델을 확보했습니다.
Acoustic Model 뿐만 아니라 저희는 Vocoder Model로 사용 중인 Hifi-GAN에 대해서도 커스텀을 하였습니다. 먼저, 발화에 활용하고자 하는 언어가 한국어라는 점에 초점을 맞추어 Hifi-GAN의 추가적인 학습을 진행하였습니다. 이외에도 음성 결과에 있어 소리의 풍부함을 확보하기 위해 Sampling Rate를 높게 설정하였습니다.
결국 풍부한 감정을 표현하는 발화로써 게임 내 다양한 상황에 어울리는 게임 특화 음성 합성이 가능해졌을 뿐만 아니라, 운율이 자연스럽고 퀄리티가 좋은 음성을 생성하는 것이 가능했습니다.
2-3. 학습 데이터
TTS 모델 학습을 위한 데이터는 한국지능정보사회진흥원에서 제공하는 AIHUB 음성 데이터와 넥슨에서 녹음된 음성 데이터를 사용했습니다. 음성 데이터는 그대로 사용하지 않고 음성 퀄리티, 음성과 스크립트 간의 매칭 여부 등 다양한 기준으로 데이터 검수하여 모델 학습에 사용했습니다. 음성 데이터에 대한 검수 전/후 데이터로 모델 학습을 진행했을 때, 검수된 데이터로 학습된 모델의 음성합성 성능이 더 좋았습니다.
2-4. 모델 학습 프로세스
학습 데이터를 설명 드렸으니, 이제 모델 학습이 어떤 프로세스로 진행되는지 설명 드리겠습니다.
Voice Creator 모델은 사전학습(Pre Training), 그리고 전이학습(Transfer Learning)과 같이 두 단계에 걸쳐 학습됩니다.
1번째 Pre Training 단계에서는 대량의 데이터를 긴 시간동안 학습시켜 다양한 목소리의 화자들에 대한 지식을 쌓고 재현할 수 있도록 하고, 2번째인 Transfer Learning 단계에서는 최종적으로 발화하고 싶은 Target 화자의 음성만 학습 시켜서 짧은 기간 내 성능을 확보합니다.
이처럼 Pre Training → Transfer Learning으로 단계를 나누어 학습을 하게 되면 다음과 같은 장점이 있습니다.
Target 화자의 데이터 양이 적더라도, 사전에 확보했던 대량의 지식을 통해 보다 준수하게 학습하는 것이 가능하다.
밑바닥부터 Target 화자 데이터를 학습하는 것보다 Transfer Learning을 진행할 때 학습 수렴 속도가 더 빠르고 안정적인 성능 확보가 가능하다.
실제로 위 학습 프로세스를 통해 학습했던 모델의 사례를 들어 설명 드리겠습니다.
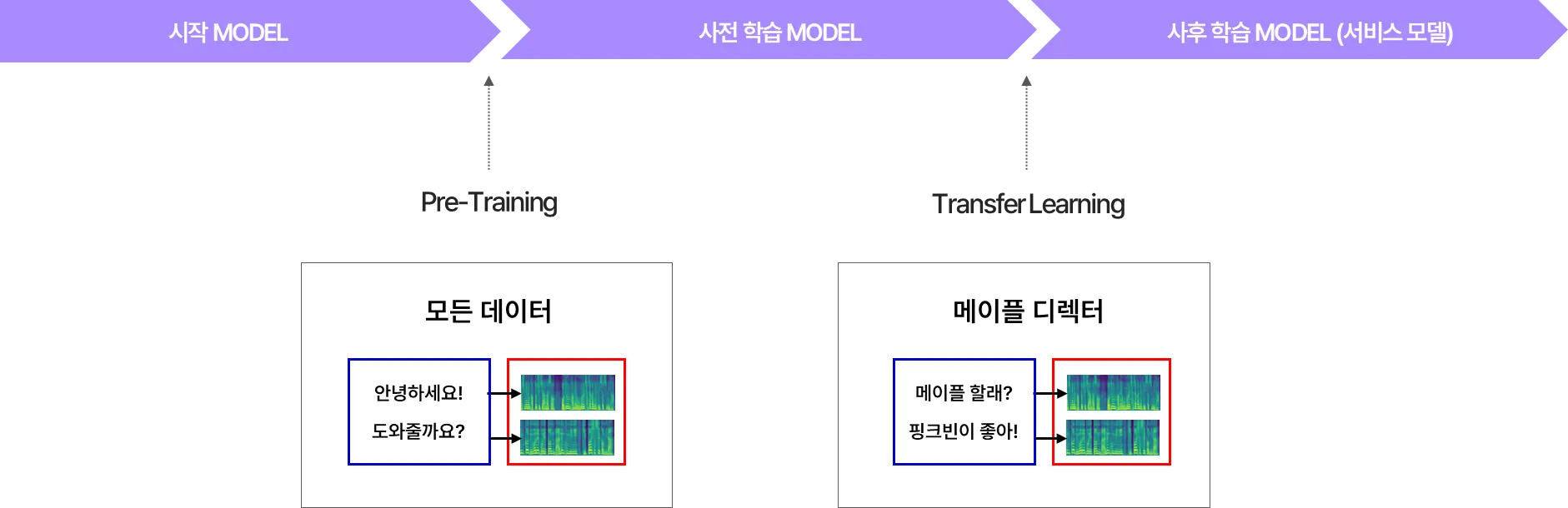
그림 4: Voice Creator 모델 학습 프로세스
위 그림처럼 1단계 학습에서는 보유 중인 모든 데이터(AIHUB, Nexon)를 학습에 활용하여 PreTrained Model을 확보합니다. 만약 메이플스토리 디렉터에 대한 목소리 발화 모델이 필요하다면 PreTrained Model을 불러온 후, 메이플스토리 디렉터 데이터셋에 대해 Transfer Learning을 진행합니다. 위 과정을 통해 메이플스토리 디렉터의 목소리를 안정적으로 내는 모델을 확보할 수 있었습니다.
2.5 Hyperparameter Search
모델의 크기와 학습 파라미터는 어떻게 효과적으로 결정할 수 있을까요?
이제 본격적으로 딥러닝 모델을 학습해야 하는데, 이를 위해서는 사전에 미리 지정해주어야 하는 여러가지 파라미터들이 있습니다.
•
learning rate
•
batch size
•
num of hidden layer
•
hidden unit size
•
dropout rate
•
etc ..
이러한 변수들을 바로 HyperParameter라 하고, 해당 값들을 어떻게 설정하는 지에 따라 모델의 성능이 차이나게 됩니다.
모델에 적합한 HyperParameter를 찾는 방법은 다양합니다.
초기에는 사람이 직접 모델의 성능을 높일 수 있을 것으로 판단되는 파라미터를 정한 뒤, 해당 파라미터의 값을 조정해가면서 최적의 파라미터를 찾았습니다.
시간이 지남에 따라 다양한 HyperParameter 서칭 방식이 등장하였고, 근래까지도 많이 사용하고 있는 방식 중 하나가 바로 Grid Search입니다.
Grid search는 모델의 성능을 높일 수 있을 것으로 판단되는 HyperParameter를 정하고, 해당 HyperParameter들의 후보 값들을 지정해 가장 높은 성능의 파라미터를 찾는 방식입니다.
하지만 여전히 파라미터에 대한 구체적인 후보 HyperParameter값들을 사람이 직접 지정해주기 때문에 설정해준 후보군들 중 최적의 값이 없다면, 모델의 최고 성능을 이끌어내기 힘들다는 한계점이 존재합니다.
그래서 저희는 HyperParameter searching 방법으로 Bayesian Optimization을 채택했습니다.
Bayesian Optimization의 가장 큰 개념적 특징은 서칭 과정에서 얻어진 각 HP값 별 모델 성능 결과를 사전지식으로 충분히 활용하는 방식이기 때문에 전체적인 HyperParameter 탐색 과정을 체계적으로 수행하고 안정적으로 최적의 HyperParameter를 찾을 수 있다는 점입니다.
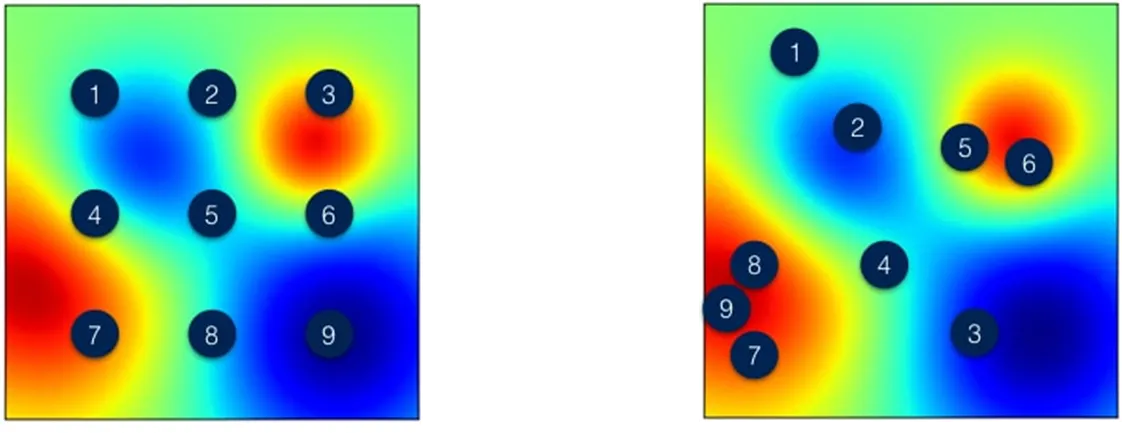
그림 5: (좌) Grid Search vs (우) Bayesian Optimization
위 그림은 Grid Search 방식과 Bayesian Optimization의 탐색 과정을 시각화로 비교해 놓은 결과입니다. 빨간색에 가까울 수록 최적의 HyperParameter에 가깝다고 할 수 있습니다. 그림에서 볼 수 있듯 좌측(Gird Search)보다 우측(Bayesian Optimization) 방법이 순차적으로 최적의 해를 잘 찾아가는 것을 볼 수가 있습니다.
아래에는 num_layer 및 hidden_size를 결정하기 위해 wandb 의 sweep 기능을 활용해 Bayesian Optimization을 수행한 결과 중 일부가 첨부되어 있습니다.
그림을 쉽게 설명하자면, 우선 오른쪽 bar는 val loss 값을 나타내고 있습니다. 따라서 그 값이 작을수록, 즉 색깔이 보라색에 해당할 수록 모델의 성능에 좋은 결과를 가져왔다는 뜻이며 보라색 선이 많이 도달한 HyperParameter별 Point들의 구성이 최적의 HyperParameter라고 볼 수 있습니다.
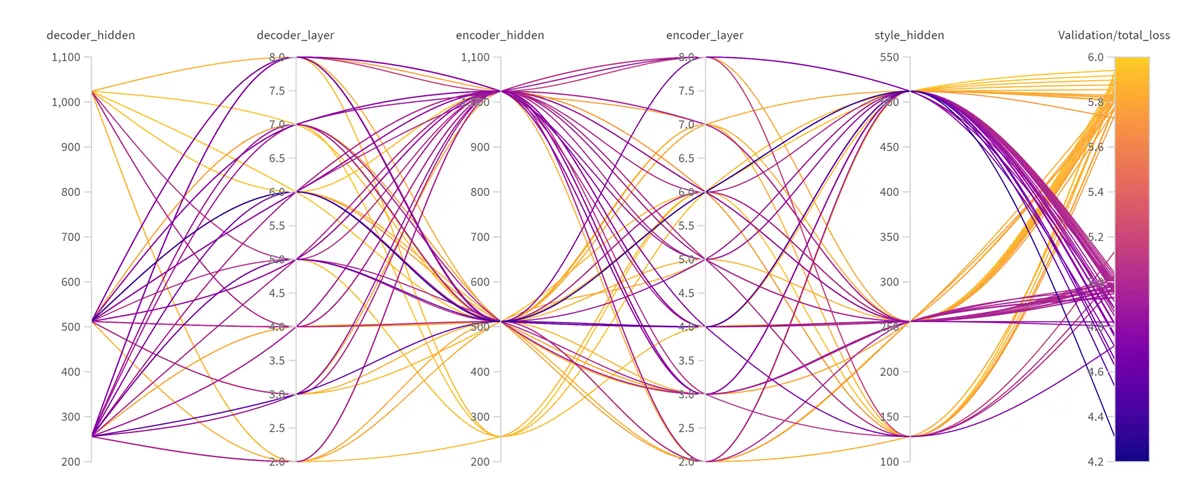
그림 6: Wandb - Sweep Result (Bayesian Optimization)
2.6 모델 성능 평가
TTS 모델이 생성한 음성의 퀄리티는 어떻게 평가할 수 있을까요?
일반적으로 논문에서는MOS (Mean Opinion Score)평가를 통해 실제 사람이 말하는 음성과 모델이 생성한 음성을 비교하게 됩니다.
MOS (Mean Opinion Score)는 음성을 사람이 직접 들어본 뒤 정해진 기준에 맞는 점수를 매겨 음성의 퀄리티를 측정하는 방법입니다. 모델은 학습 과정에서 보지 못한 스크립트에 대해 음성을 생성하고, 해당 음성을 MOS 평가에 사용하여 모델의 성능을 판단하게 됩니다.
저희는 아래와 같이 MOS평가에 대한 점수를 척도를 만들었습니다.
•
5 - 매우 좋음: 음성에 대한 퀄리티가 매우 좋으며 화자 음성과 매우 유사하다.
•
4 - 좋음: 음성 이해에 원활하며 실제 화자 음성과 유사하다.
•
3 - 보통: 음성 이해에 문제가 없고, 큰 문제가 없다.
•
2 - 좋지 않음: 음성에 있어서 노이즈가 존재하며 잘 이해할 수 없다.
•
1 - 매우 좋지 않음: 음성이 들리지 않고, 노이즈가 강하다.
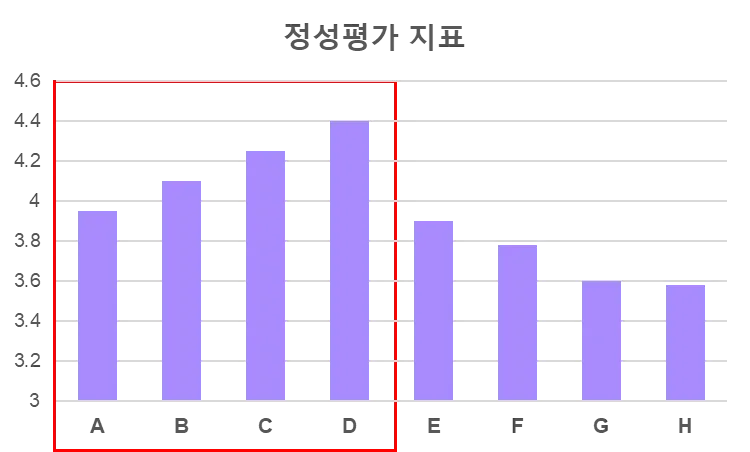
그림 7: MOS 정성 평가 결과
정성 평가의 한계점
다양한 모델 구조 및 파라미터로 모델 학습을 진행하면서 모델 성능을 평가해야 되는 상황이 빈번하게 발생했습니다. 모델을 평가할 때마다 매번 MOS평가를 위해 사람들이 직접 들어보고 평가하는 일은 쉽지 않습니다.
사람이 직접 들어보지 않고 평가할 수 있는 방법이 있으면 좋지 않을까요?
저희는 생성된 음성의 퀄리티를 직접 듣지 않고 평가할 수 있는 2가지 방법을 찾아 활용하게 되었습니다.
MCD(mel-cepstral distortion)와 Spectral flatness 지표를 활용한 정량 평가
MCD(mel-cepstral distortion)
실제 음성과 생성된 음성의 차이를 나타내는 측정 지표로 그 값이 작을수록 생성된 음성의 퀄리티가 좋음을 나타냅니다.
Spectral flatness
음성이 노이즈와 얼마나 유사한지 측정하는 지표로써 0~1 사이 값을 가지고 1에 가까울수록 음성은 white noise에 가까움을 확인할 수 있습니다.
정량 평가로 정성 평가를 대체할 수 있을까요?
MCD와 Spectral flatness는 MOS와 달리 수치가 낮을수록 결과가 좋은 지표입니다. 아래 차트를 보시면 MOS 평가에서 높은 점수를 받았던 화자는 정량 평가에서도 좋은 결과가 나타나는 것을 통해 두 가지 평가 방식의 추이가 비슷하다고 판단했습니다. 이에, 정성 평가를 완전히 대체하기는 어렵지만, 빈번하게 발생하는 모델 성능 비교에 활용하고 있습니다.
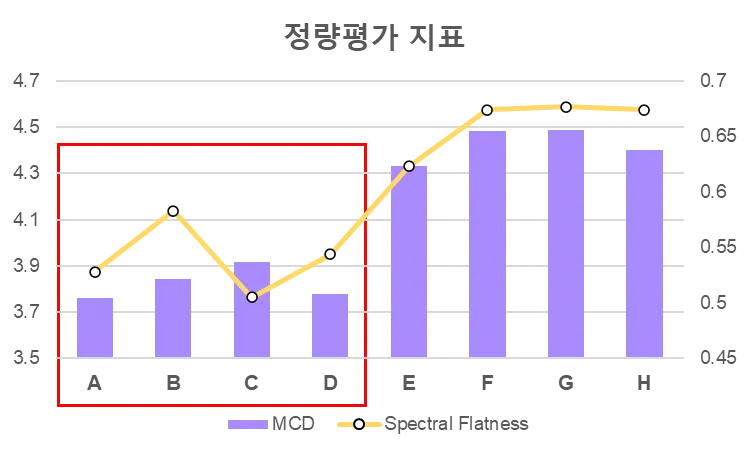
그림 8: MCD / Spectral Flatness 정량 평가 결과
3. Voice Creator AI 활용 사례
Voice Creator에 등록되어 있는 AI 화자 일부와 활용 사례에 대해 소개 드리겠습니다.
3.1 메이플스토리 디렉터
첫 번째 AI 화자는 메이플스토리 디렉터 입니다.
왼쪽 샘플 음성은 개발 초기 모델로 생성한 음성이고, 오른쪽 샘플 음성은 Voice Creator로 생성한 음성입니다.
Sample A
•
스크립트 - 메이플스토리와 5,320일을 함께 해주셔서 감사드립니다.
Sample B
•
스크립트 - 팡이요님의 메이플 복귀를 환영합니다. 내일도 와주실 거죠?
Voice Creator로 생성한 음성은 30분 분량의 녹음 데이터에 대해 모델을 학습시키고 생성해낸 결과입니다. 소량의 데이터만을 활용하더라도 메이플스토리 디렉터의 목소리를 잘 반영하고 있습니다.
3.2 하프타임 GM네로

그림 9: M네로의 하프타임 영상 썸네일
두 번째 AI 화자는 GM네로 입니다.
넥슨에서는 피파온라인4의 업데이트 소식을 전달하는 다양한 방법 중 하나로 GM네로의 하프타임 유튜브 콘텐츠를 발행하고 있습니다. 현재는 Voice Creator가 음성 제작에 활용되어 아래와 같은 프로세스를 개선해 나가고 있습니다.
1. 영상 스크립트 녹음 프로세스 개선
•
하프타임 음성 녹음을 위해 아래와 같은 프로세스를 가지고 있지만, Voice Creator를 사용하면서 녹음 시간을 단축해 리소스를 절감하고 있습니다.
◦
스크립트 작성 → 사업/개발 협의 → 사운드팀과 일정 협의 후 스크립트 녹음
2. 음성 재녹음 프로세스 개선
•
영상 스크립트 내 수정 사항이 생길 경우, 재녹음을 하지 않아도 되는 장점을 가지게 됩니다. 이에, 긴급히 수정해야 할 상황에서 빠른 대응이 가능합니다.
또한, Voice Creator는 해당 콘텐츠에 대한 녹음 음성을 확보하고 모델 학습에 활용하고 있습니다.
아래 샘플은 23년 5월 25일에 발행된 GM네로의 하프타임 48화 콘텐츠의 원본 음성 일부와 23년 4월에 학습된 모델로 생성한 음성의 퀄리티를 비교해볼 수 있습니다. 오른쪽 샘플은 학습 데이터에는 포함되지 않았던 텍스트에 대하여 생성한 음성 합성 결과입니다. 아래 샘플을 통해 GM네로의 음색과 발화 스타일을 적절하게 복제하고 있음을 확인하실 수 있습니다.
Sample
•
스크립트 - 첫 번째로 안내 드릴 소식은 아이콘 선수들의 커리어 정점, 그 순간을 상징하는 아이콘 더 모먼트 클래스입니다!
4. Voice Conversion
Voice Creator는 생동감 있는 다양한 목소리를 재현하기 위해 지속적인 노력을 기울이고 있습니다.
이를 위해 필요한 다양한 기술들 중 Voice Conversion 기술에 대한 연구를 진행하고 있습니다.
Voice Conversion 기술은 아래와 같은 Task에 활용할 수 있습니다.
1.
가수가 부른 노래를 내가 원하는 사람의 목소리로 부르도록 변환
2.
스포츠 캐스터가 해설하는 음성을 원하는 사람의 목소리로 변환
3.
연출력이 출중한 성우의 음성으로부터 연출력은 유지하면서 다른 사람의 목소리로 변환
Voice Conversion 기술 활용에 대한 예시로 SVC(Singing Voice Conversion) 기술을 이용해
메이플스토리 디렉터이 혁오의 “위잉위잉”을 부를 수 있도록 만들어 보겠습니다.
SVC(Singing Voice Conversion) 란?
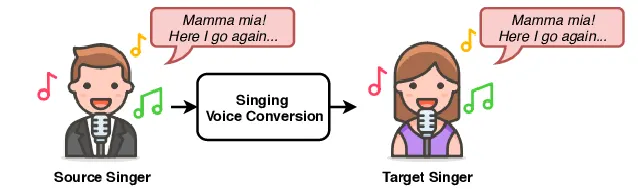
그림 10: Singing voice conversion process
SVC는 사람 A가 부르는 노래를 사람 B가 부르는 것처럼 만들 수 있는 Task 입니다.
예를 들어, 성시경이 부르는 “희재"라는 곡을 제 목소리로 부를 수 있도록 만들 수도 있습니다.
SVC 기술을 어디에 활용할 수 있을까요?
유튜브 또는 푸시 메시지 등 마케팅 콘텐츠 제작에 활용할 수 있습니다. 내가 좋아하는 노래를 내가 좋아하는 게임 캐릭터의 음성으로 부를 수 있도록 만들 수 있습니다. 이를 통해 유저들에게 재밌고 새로운 경험을 제공해볼 수 있습니다.
SVC 기술 적용
메이플스토리 디렉터이 혁오의 “위잉위잉”을 부를 수 있도록 만들기 위해 Lora-SVC 오픈소스[5]를 이용했습니다. Lora-SVC 모델은 아래와 같이 각 Task에서 좋은 결과를 보이는 모델 및 아이디어를 활용해 만들어졌습니다.
Whisper
구분 | 정보 |
개발사 | OpenAI (2022) |
기능 | 자동음성인식 (ASR) |
특징 | 웹상에서 수집한 680,000 시간의 다언어 음성 데이터로 학습 |
자료 |
BigVGAN
구분 | 정보 |
개발사 | NVIDIA (2023) |
기능 | Mel-Spectrogram을 Audio로 변환 |
특징 | 모델이 보지 못했던 화자, 언어, 녹음 환경에 대해서도 높은 퀄리티의 오디오 변환이 가능. |
자료 |
ADASPEECH
구분 | 정보 |
개발사 | Microsoft (2021) |
기능 | 오디오 및 스크립트 정보를 이용해 Mel-Spectrogram 생성 |
특징 | Fine tuning을 통해 새로운 화자에 대한 보이스 복제 |
자료 |
Lora-SVC 모델로 음성을 생성하기 위해선 아래의 준비물은 필요합니다.
•
모델 학습을 위한 30분 분량의 메이플스토리 디렉터 음성 파일
•
MR이 제거된 혁오의 “위잉위잉” 음성 파일
그리고, Lora-SVC 오픈소스의 가이드에 따라 진행하면 아래와 같은 괜찮은 수준의 결과물을 얻을 수 있습니다.
현재는 노래를 Input으로 받아 목소리를 변환하는 Singing Voice Conversion Task를 우선적으로 R&D하였지만, 향후에는 게임 성우 목소리를 Input으로 받아 목소리를 변환할 수 있는 Voice Conversion Task에 대한 리서치도 진행할 예정입니다.
나가며 : 맺는 말
지금까지 Nexon Voice Creator에 대한 소개와 활용 예시에 대해 말씀드렸습니다. 본문에서 제시한 사례들 외에도 다양한 분야에 AI 보이스를 적용할 수 있습니다. 이에 맞추어 Voice Creator 모델 또한 성능 개선 및 여러 기능들의 추가가 이루어질 계획입니다. 지속적으로 발전해나갈 Voice Creator의 모습에 많은 관심 부탁 드리겠습니다. 읽어주셔서 감사합니다.
Reference
[5] Lora-SVC, GitHub
 함께 읽으면 좋은 콘텐츠
함께 읽으면 좋은 콘텐츠 









 테크블로그 문의 gs_site_contents@nexon.co.kr
테크블로그 문의 gs_site_contents@nexon.co.kr