

Table of contents
들어가며

안녕하세요, 인텔리전스랩스 분석가 백상현입니다. 
오늘은 XGBoost, LightGBM, RandomForest와 대등한 성능을 가지면서, 의사결정 과정이 설명 가능한 Explainable Boosting Machine의 원리와 라이브러리 사용 방법, 활용 사례에 대해 알아보겠습니다.
설명 가능한 머신러닝 모델의 장점
오늘날 머신러닝은 많은 분야에서 사용되고 있습니다. 드라마 추천, 게임 매칭 등 일상적인 영역부터 대출 심사, 암 진단, 투자 결정 같은 하이 리스크의 영역까지 다양한 분야에서 머신러닝이 사용되고 있습니다. 머신러닝 모델의 역할이 계속 커지는 상황에서 머신러닝 모델의 의사결정 과정을 이해하고 해석하는 것 또한 중요한 주제로 떠오르고 있습니다.
머신러닝 모델은 크게 White-box 모델과 Black-box 모델로 구분할 수 있습니다. 모델의 의사결정 과정이 간단하고 해석 가능한 모델을 White-box 모델이라고 하며, 반대로 구조가 복잡하고 의사결정 과정을 해석하기 어려운 머신러닝 모델을 Black-box 모델이라고 합니다.
의사결정 과정 설명이 가능한 White-box 모델은 많은 장점이 있습니다:
•
모델 디버깅
설명 가능성이 높은 모델을 사용하면 단순히 모델의 잘못된 예측을 관찰하는 것을 넘어서 잘못된 예측의 의사결정 과정을 확인할 수 있습니다. 이를 기반으로 overfitting의 징후를 찾고, 문제를 일으키는 데이터 전처리 과정을 찾는 등 모델 디버깅을 수월하게 진행할 수 있습니다.
•
공정성 이슈 확인
모델에 공정하지 못한 bias가 존재하는지 확인할 수 있습니다.
•
모델 신뢰성
의사결정 과정을 확인할 수 있는 모델은 사람이 더 신뢰할 수 있고, 머신러닝 도메인 지식이 없는 사람들에게 설명하기 용이합니다.
•
하이 리스크 의사결정
의료, 금융 같은 산업 분야에서 머신러닝 모델을 사용한다면 잘못된 예측의 리스크가 매우 큽니다. 설명 가능성이 높은 모델을 사용한다면 모델의 예측을 무작정 믿지 않고, 모델의 의사결정 과정을 검토하며 sanity check를 진행할 수 있습니다.
하지만 설명 가능한 모델의 장점이 이렇게 많음에도 불구하고 현재 가장 많이 사용되는 머신러닝 모델들은 대부분 Black-box 모델입니다.
Accuracy - Interpretability Trade-off
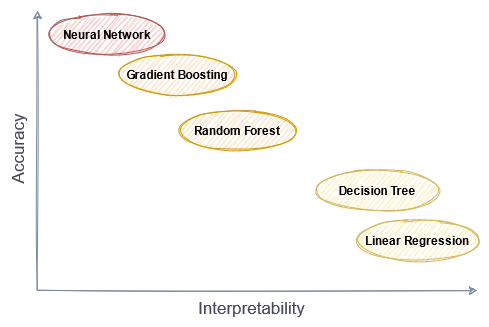
그림 1 : The interpretability - Accuracy Trade-Off
White-box 모델이 자주 사용되지 않는 이유는 설명 가능한 머신러닝 모델의 예측 성능이 보편적으로 좋지 않기 때문입니다.
선형회귀, 의사결정 나무처럼 구조가 간단하고 설명이 용이한 머신러닝 모델들은 데이터 간의 복잡한 관계를 표현할 수 없고 예측 성능이 좋지 않습니다. 반대로 부스팅 모델, 딥러닝 모델처럼 데이터 간의 복잡한 관계를 표현할 수 있는 머신러닝 모델들은 의사결정 과정을 해석하기 어렵습니다.
이처럼 머신러닝에서 모델의 예측 정확도와 설명 가능성이 trade-off 관계를 보인다는 것은 정설처럼 받아들여져 왔고, Accuracy - Interpretability Trade-off라는 용어도 존재합니다. 즉, 우수한 예측 성능과 설명 가능성을 모두 가지는 모델은 없다고 생각되었습니다.
Explainable Boosting Machine (EBM)
그러나 마이크로소프트의 interpretML 패키지에 포함된 Explainable Boosting Machine(EBM)은 우수한 예측 성능과 설명 가능성 두 마리 토끼를 모두 잡았습니다.
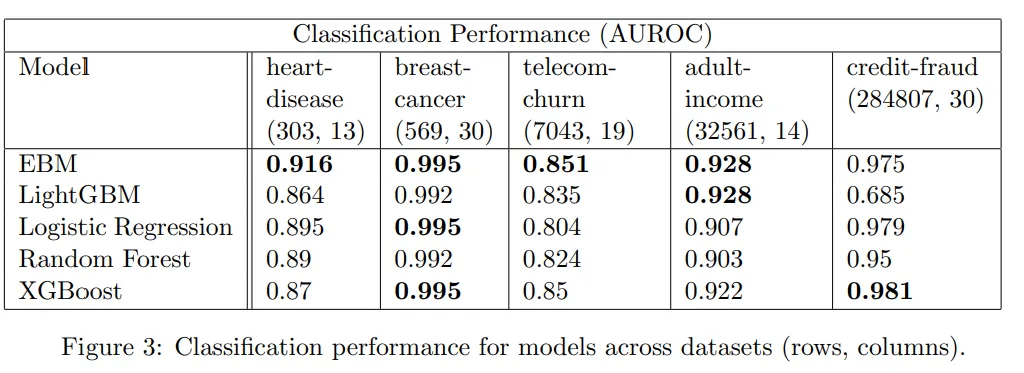
그림 2 : Classification performance for models across datasets
위 표는 5개의 공개 데이터셋에 EBM, LightGBM, 로지스틱 회귀, 랜덤 포리스트, XGBoost 분류 모델을 학습시킨 결과입니다. EBM은 높은 설명 가능성을 가지고 있음에도 불구하고, LightGBM, 랜덤 포리스트, XGboost같은 모델들과 동등한 수준의 성능을 보입니다.
이는 EBM을 활용한다면 더 이상 높은 예측 정확도를 확보하기 위해 설명 가능성을 포기할 필요가 없다는 것을 의미합니다!
EBM 모델 구조
EBM의 모델 구조에 대해서 살펴보겠습니다. EBM은 Generalized Additive Model (GAM)의 발전된 형태인 GA2M 모델의 한 종류입니다.
GAM과 GA2M에 대해서 이미 알고 계시지 않다면, 위 설명만으로 EBM 모델 구조가 쉽게 이해되지 않을 것입니다. 그러므로 먼저 GAM, GA2M이 무엇인지 살펴본 후 EBM의 모델 구조에 대해서 다시 설명해 보겠습니다.
Generalized Additive Model (GAM)
아래의 형태로 구성된 예측 모델을 Generalized Additive Model (GAM)이라 부릅니다.
를 link function이라 지칭하고, 1개의 feature를 입력으로 받는 함수 를 shape function이라고 부릅니다.
•
regression task에서 는 identity function이고 :
•
classification task에서 는 logistic function입니다:
GAM은 선형 회귀, 로지스틱 회귀처럼 각 feature에 대한 연산 값의 합을 의사결정에 활용하기 때문에 각 feature가 의사결정에 어떤 영향을 미치는지 파악하기 쉽습니다. 그러면서도 선형 회귀, 로지스틱 회귀에 비해 GAM은 feature와 target 값의 비선형적인 관계를 더 잘 표현할 수 있어 linear model에 비해 예측 성능이 훨씬 좋습니다.
하지만 GAM은 feature 간의 상호 작용( 의 pairwise interaction)을 표현할 수 없다는 한계점이 있습니다.
Note: Gradient Boosting 같은 Full Complexity Model은 ( 형태로 예측을 하기 때문에 각 feature가 의사결정에 어떻게 기여하는지 쉽게 파악할 수 없습니다.
Generalized Additive Model plus Interactions (GA2M)
feature 간의 상호 작용을 표현할 수 없는 GAM의 한계를 극복하기 위해 pairwise interaction term이 추가된 모델이 Generalized Additive Model plus Interactions (GA2M)입니다.
수학적으로 표현해 보면 아래의 형태를 따르는 예측 모델이 Generalized Additive Model plus Interactions (GA2M)입니다.
GA2M에서는 GAM의 모델 형태에 추가적으로 feature 간의 상호 작용을 표현해 주는 pairwise interaction term 이 추가된 것을 확인할 수 있습니다. 추가된 pairwise interaction term은 2개 피처 간의 상호작용을 모델이 표현할 수 있도록 해줍니다.
pairwise interaction term는 2개의 feature를 입력으로 받는 함수이기 때문에 pairwise interaction이 의사결정에 미치는 영향을 파악하는 것이 상대적으로 비직관적이라는 문제가 있습니다. 그래도 를 평면에 heatmap 형태로 시각화하면 해당 term의 의사결정 기여를 어렵지 않게 이해할 수 있습니다.
pairwise interaction term 을 모델에 포함하면 발생하는 또 다른 문제가 있습니다. feature 수가 많아지면 모델에 포함해야 할 pairwise interaction term의 수도 폭발적으로 증가한다는 것입니다. GA2M 모델의 사이즈가 과도하게 커지는 것을 방지하지 위해 통계적으로 유의한 또는 가장 중요한 상위 k 개의 pairwise interaction만을 모델에 포함할 필요가 있습니다.
pairwise interaction 검증/선택은 전통적으로 ANOVA , Partial Dependence Function, GUIDE, Grove 등 기법을 이용해서 진행되었습니다.
Explainable Boosting Machine (EBM)
지금까지 GAM, GA2M에 대해 간략하게 알아보았습니다. 이제 “EBM은 Generalized Additive Model (GAM)의 발전된 형태인 GA2M 모델의 한 종류입니다.”라는 설명이 대략 이해가 되었을 것 같습니다. EBM은 다른 GA2M 모델과 동일하게 의 구조를 가집니다.
EBM이 기존 GA2M 모델과 다른 점으로는:
1.
shape 로 1개의 feature만 사용할 수 있는 gradient boosting model 등 머신러닝 모델을 사용합니다.
2.
FAST라는 자체 개발 알고리즘으로 모델에 포함할 pairwise interaction term k 개를 선택합니다.
3.
pairwise interaction term 로 2개의 feature를 사용할 수 있는 gradient boosting model과 같은 머신러닝 모델을 사용합니다.
즉, EBM 내부에는
1.
모든 feature마다 자신만을 입력으로 받는 gradient boosting 모델이 있고
2.
feature 2개를 입력으로 받는 gradient boosting 모델 k 개가 있습니다.
데이터가 주어지면 EBM 내부에 있는 모든 gradient boosting 모델의 예측값과 intercept 값의 합을 예측값으로 사용합니다.
EBM regressor의 경우 내부 gradient boosting 모델 예측값과 intercept 값의 합이 바로 예측값이 되고
EBM classifier의 경우 내부 gradient boosting 모델 예측 값과 intercept 값의 합이 로짓 값이되는 형태입니다.
EBM 학습 과정
다음으로는 EBM의 학습 과정을 살펴보겠습니다.
EBM의 학습은 크게 2 단계로 진행됩니다:
1.
gradient boosting으로 pairwise interaction을 고려하지 않은 학습
2.
FAST 알고리즘으로 모델에 포함할 feature interaction term 선택 및 학습
1. gradient boosting으로 pairwise interaction을 고려하지 않은 GAM 모델 학습

그림 3 : Gradient Boosting for Regression in Generalized Additive Models
pairwise interaction을 고려하지 않은 학습은 위 알고리즘을 통해 이루어집니다.
기존 부스팅 기법과 유사하게 데이터에 얕은 트리를 피팅하고, 다음 트리는 이전 트리의 residual을 예측하도록 학습시키는 과정을 밟습니다.
하지만 기존의 부스팅 기법과 다르게 1개의 트리는 1개의 feature만 사용할 수 있도록 제한됩니다. 또한 이전 트리 잔차를 예측하는 다음 트리는 아직 사용하지 않은 feature 1개를 사용하게 되고, 모든 feature를 트리 학습에 1번씩 사용하면 1번의 학습 사이클 종료된다는 점도 EBM 학습 알고리즘의 고유한 특징입니다.
좀 더 직관적으로 이해할 수 있도록 시각적으로 표현해 보자면 다음과 같습니다:
첫 번째 decision tree는 feature1만을 사용할 수 있게 제한되어 학습됩니다.
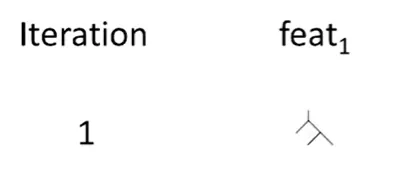
그림 4 : Algorithm Sketch: fitting small tree on single feature
다음 decision tree는 첫 번째 decision tree의 잔차를 예측하도록 학습되고 이전에 사용되지 않은 feature (feat1이 아닌) 1개만 사용할 수 있습니다.
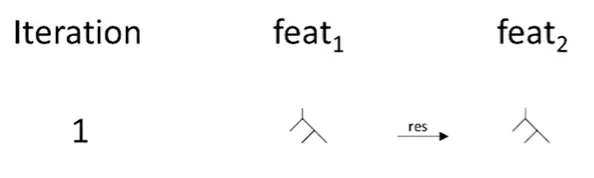
그림 5 : Algorithm Sketch: fitting small tree with unused feature
이런 형식으로 모든 feature를 순차적으로 사용해서 decision tree를 학습 시키면 한 학습 iteration이 완료됩니다. EBM을 학습 시킬 때는 학습 iteration 내의 feature 사용 순서가 무의미하도록 아주 작은 learning rate를 사용합니다.

그림 6 : Algorithm Sketch: single training iteration
이 학습 iteration을 M 번 반복합니다.

그림 7 : Algorithm Sketch: complete tree fitting algorithm
M iteration이 완료되면 EBM GAM 모델 학습이 종료됩니다.
학습이 완료된 후에는 feature 별로 자신만을 사용하는 decision tree가 M 개씩 생성됩니다. 메모리 효율을 위해 feature 별 tree M 개의 출력값 합을 lookup table (graph)로 변환하고 트리를 삭제합니다.
이후 예측을 진행할 때는 lookup table만을 사용합니다. 예를 들어 이 주어지면 을 입력으로 사용하는 M 개의 tree의 출력값을 계산하고 합하는 것이 아닌 lookup table로 바로 값을 계산합니다.

그림 8 : Algorithm Sketch: converting trees to lookup table
2. FAST 알고리즘으로 모델에 포함할 feature interaction term 선택 및 학습
pairwise interaction을 고려하지 않은 GAM 모델 학습이 완료된 후 feature interaction term 를 모델에 추가해 줍니다.
앞서 언급했듯이 feature의 수가 많아지면 존재하는 feature pair 조합의 수는 감당하기 어려울 정도로 커집니다. 그러므로, 수많은 feature interaction term 중 어떤 interaction term을 모델에 포함할지 결정하는 과정이 필요합니다.
EBM은 FAST라는 자체 개발 알고리즘을 이용해 어떤 interaction term을 모델에 포함할지 결정합니다.
FAST 알고리즘의 철학은 다음과 같습니다:
존재하는 모든 조합을 구하고 조합별로 2개의 feature를 사용하는 부스팅 모델 를 학습시킨다면,의 interaction이 강할수록 해당 부스팅 모델 의 예측 성능도 좋을 것(RSS가 낮다)이라는 가정하에 FAST 알고리즘은 출발합니다.
하지만 존재하는 모든 를 부스팅 방식으로 학습시켜서 RSS를 비교하는 것은 컴퓨팅 비용이 너무 크기 때문에 현실적이지 못한 방법입니다.
그러므로 FAST 알고리즘은 평면에 2개의 직선 cut 를 생성하고 각 quadrant에 속하는 데이터의 평균값을 예측값으로 사용하는 간단한 모델을 만들어 부스팅 모델의 성능을 추정합니다. 이 추정용 모델을 interaction predictor ()라고 지칭합니다.
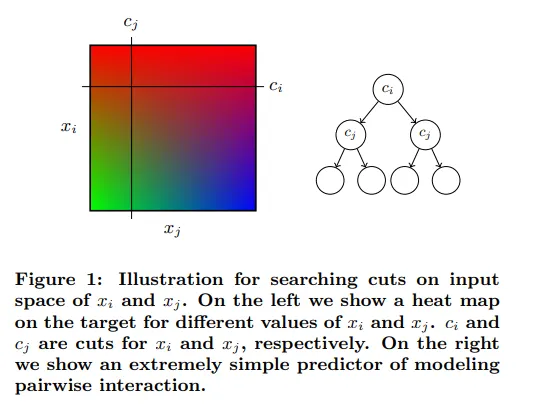
그림 9 : Using FAST algorithm to build an simple model for using cuts on the input space of and
학습은 모든 조합을 탐색하여가 가장 낮은 최적를 선택하는 방식으로 진행됩니다. 가장 낮은 RSSRSS 값을 가지는 에 해당하는 를 가장 중요한 interaction이 발생하는 feature pair로 간주합니다.
이후 interaction이 높은 상위 K 개 feature pair를 선택하고, 이전 방식과 동일한 부스팅 방식으로 모델 잔차에 2개 feature를 사용할 수 있는 tree들을 학습시켜 모델 학습을 마무리합니다. 2개 feature를 사용하는 tree는 학습은 학습 과정 1이 끝나고 생성된 GAM 모델의 잔차를 예측하도록 진행됩니다. EBM을 지원하는 공식 라이브러리 InterpretML 팀이 pairwise interaction term의 학습 방식은 라이브러리가 업데이트되며 변경될 가능성이 있다고 밝힌 점도 참고하시면 좋을 것 같습니다.
라이브러리 사용 방법
카트라이더 유저의 라이센스를 예측하는 간단한 EBM 분류 모델 예제를 통해 interpretML 라이브러리의 EBM 모델 사용 방법을 살펴보겠습니다.
카트라이더에는 타임 어택, 대결 등 미션을 클리어하면 획득할 수 있는 라이센스 시스템이 존재합니다. 획득할 수 있는 라이센스 종류는 초보, 루키, L3, L2, L1, Pro가 있고, 라이센스의 획득 난이도는 나열 순서대로 높아집니다.
그림 10 : 카트라이더 라이센스 관리 페이지
카트라이더 주행 기록으로 유저의 라이센스를 예측해 볼 수 있지 않을까요? 90일간의 유저 스피드전 주행 기록으로 유저의 라이센스가 L2 이상인지 예측하는 EBM 모델을 만들어보겠습니다.
사용 데이터:
Feature:
difficulty_1_record_mean : 지난 90일간 난이도 1 트랙 기록 평균
difficulty_2_record_mean : 지난 90일간 난이도 2 트랙 기록 평균
difficulty_3_record_mean : 지난 90일간 난이도 3 트랙 기록 평균
difficulty_4_record_mean : 지난 90일간 난이도 4 트랙 기록 평균
difficulty_5_record_mean : 지난 90일간 난이도 5 트랙 기록 평균
difficulty_6_record_mean : 지난 90일간 난이도 6 트랙 기록 평균
difficulty_1_record_min : 지난 90일간 난이도 1 트랙 최고 기록 (최솟값) difficulty_2_record_min : 지난 90일간 난이도 2 트랙 최고 기록 (최솟값) difficulty_3_record_min : 지난 90일간 난이도 3 트랙 최고 기록 (최솟값) difficulty_4_record_min : 지난 90일간 난이도 4 트랙 최고 기록 (최솟값) difficulty_5_record_min : 지난 90일간 난이도 5 트랙 최고 기록 (최솟값) difficulty_6_record_min : 지난 90일간 난이도 6 트랙 최고 기록 (최솟값)
Feature 생성: 지난 90일간 모든 유저의 주행 기록을 트랙별로 그룹화하고 1부터 100 사이의 값을 가지도록 minmax 스케일링을 진행했습니다. 트랙별로 스케일링 된 주행 기록을 이용해 유저별 트랙 난이도별 주행 기록 평균과 최솟값을 구했습니다.
Target:
license : 유저의 라이센스가 L2 이상인지 (Boolean)
Target으로 유저의 라이센스가 L2 이상이면 True인 label을 생성했습니다.
모델링 예시
EBM을 사용하기 위해서 intrepretML 라이브러리를 설치합니다.
! pip install interpret
라이브러리 설치가 완료되면 모델링에 필요한 라이브러리를 불러옵니다.
from interpret.glassbox import ExplainableBoostingClassifier
from interpret import show
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, KFold
from sklearn.metrics import accuracy_score, f1_score
from imblearn.over_sampling import RandomOverSampler
from hyperopt import fmin, tpe, hp, SparkTrials, STATUS_OK, Trials, space_eval
from datetime import datetime, date
Python
복사
interpretML EBM은 scikit-learn 스타일의 API를 제공합니다. 그러므로, 익숙한 .fit() .predict() 메서드를 사용해서 간편하게 모델링을 진행할 수 있습니다. 또한 기존에 scikit-learn과 함께 사용하던 라이브러리, 메서드들도 코드 수정 없이 사용할 수 있습니다. 예를 들어 hyperopt 라이브러리를 통한 하이퍼 파라미터 튜닝 코드도 아래 예시에서처럼 수정 없이 사용할 수 있습니다.
# define loss
def ebm_objective(params):
print(params)
all_f1 = []
kf = KFold(n_splits=3, shuffle=True,random_state=8)
for train_idx, val_idx in kf.split(X_train):
X_trainCV, X_valCV = X_train.iloc[train_idx], X_train.iloc[val_idx]
y_trainCV, y_valCV = y_train.iloc[train_idx], y_train.iloc[val_idx]
ebm = ExplainableBoostingClassifier(**params)
ebm.fit(X_trainCV, y_trainCV)
y_predCV = ebm.predict(X_valCV)
f1 = f1_score(y_valCV, y_predCV)
all_f1.append(f1)
score = np.mean(all_f1)
return {"loss": -score, "status": STATUS_OK}
# load data and preprocess
# X_train, X_test, y_train, y_test = ...
# define search space
space = {
"learning_rate": hp.choice("learning_rate", [0.001, 0.01, 0.05]),
"early_stopping_rounds": hp.choice("early_stopping_rounds", np.arange(50,500,50,dtype=int)),
"binning": hp.choice("binning", ["uniform", "quantile", "quantile_humanized"]),
"max_leaves" : hp.choice("max_leaves", np.arange(2,16,dtype=int))
}
# hyperparameter tuning
trials = Trials()
best_ebm_space = fmin(
fn=ebm_objective,
space = space,
algo=tpe.suggest,
max_evals=100,
trials=trials
)
best_ebm_param = space_eval(space, best_ebm_space)
print("Best: {}".format(best_ebm_param))
Python
복사
학습된 EBM 모델의 성능은 accuracy: 0.86, f1-score: 0.78로 다른 부스팅 모델과 비슷한 수준을 보입니다.
LightGBM: accuracy: 0.85, f1_score: 0.77
XGBoost: accuracy: 0.86, f1_score: 0.77
In:
# train model on entire train data
final_ebm = ExplainableBoostingClassifier(**best_ebm_param)
final_ebm.fit(X_train, y_train)
y_pred = final_ebm.predict(X_test)
# final evaluation of model
acc = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print("accuracy: {}".format(acc))
print("f1_score: {}".format(f1))
Out:
accuracy: 0.8646383757795871
f1_score: 0.7804987836322284
Python
복사
EBM 모델이 훈련 완료되면 .explain_global() .explain_local() 메서드로 모델 내부 구조와 의사결정 과정을 살펴볼 수 있습니다.
.explain_global() 메서드로 학습된 EBM 모델의 feature importance, feature function , 그리고 interaction term 을 확인할 수 있습니다. .explain_local() 메서드는 EBM 모델이 특정 데이터를 특정 label로 추론한 이유를 보여줍니다.
아래 코드를 실행하면 EBM 모델의 global explanation을 interactive 하게 보여줍니다. Dropdown 메뉴를 이용해서 feature importance, feature function, interaction term을 확인할 수 있습니다. 또한 커서를 그래프에 올리면 해당 지점의 값이 표시됩니다.
global_explanation = ebm_model.explain_global()
show(global_explanation)
Python
복사
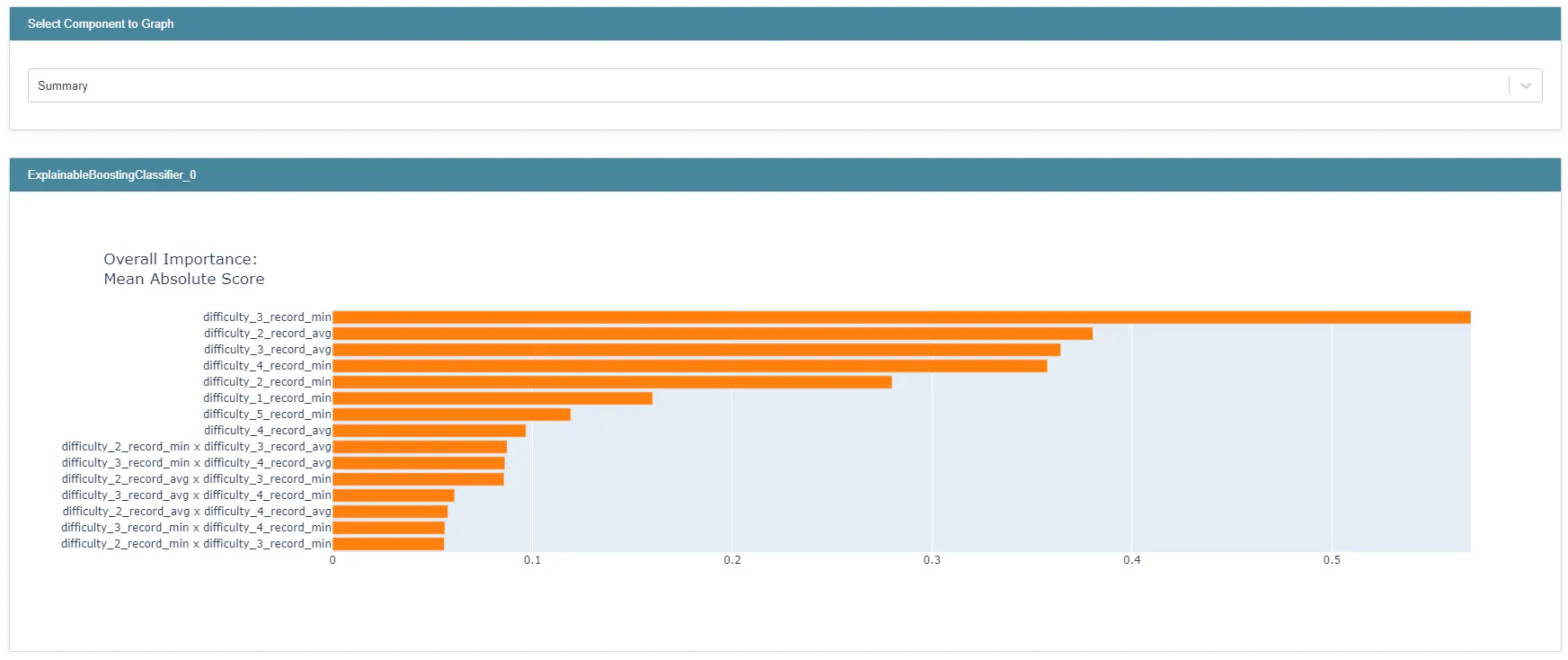
그림 11 : top 15 features
드롭다운 메뉴에서 Summary를 선택하면 feature_importance가 가장 높은 15개 feature를 확인할 수 있습니다.
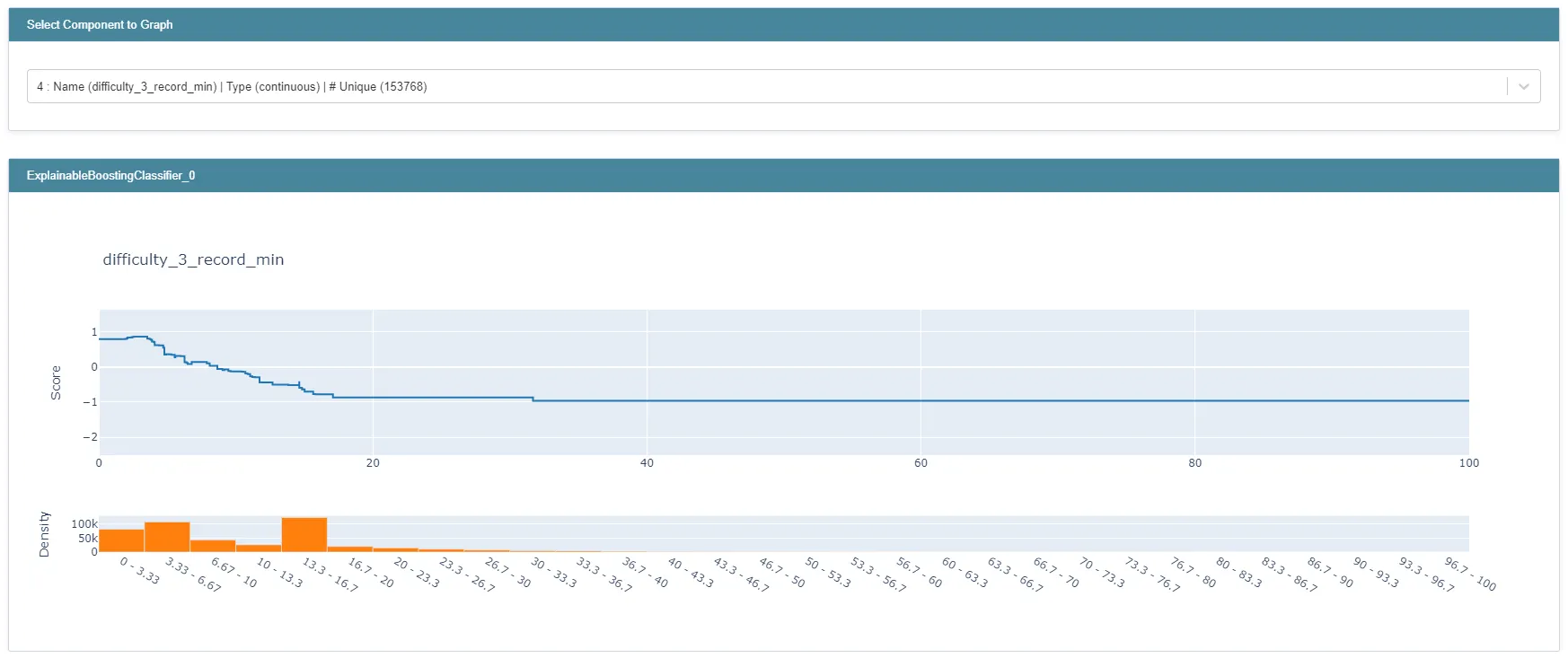
그림 12 : feature별 feature function 예시
상단 드롭다운 메뉴를 이용해서 feature 별 feature function()을 확인할 수 있습니다. 위 그래프는 difficulty_3_record_min만을 사용하는 decision tree들을 lookup table로 대체한 결과입니다. 앞에서 설명해 드렸듯이 difficulty_3_record_min 값이 주어지면, 위 그래프를 이용해 값을 바로 계산합니다.
난이도 3 트랙의 최고 기록이 좋을수록 L2 라이센스 이상일 확률이 커진다고 모델이 판단하고 있다는 것을 위 그래프를 통해서 확인할 수 있습니다. 모델이 직관적으로 이해할 수 있는 의사결정을 하고 있다는 것을 확인할 수 있습니다.
만약 feature function의 모양이 직관적으로 이해가 가지 않는 경우가 있다면, 그 결과로 모델 디버깅을 수행할 수 있습니다. 데이터 수집 과정, 데이터 전처리 과정에서 문제가 될 부분이 있는지 고민해 볼 수 있고, 추가로 고려하지 못하고 있는 상황이 있는지도 생각해 볼 수 있습니다.
블로그 포스트의 마지막 부분에서 EBM feature function을 통해 데이터 전처리 과정에서 발생하는 문제를 파악했던 실제 사례를 소개해 드리겠습니다.
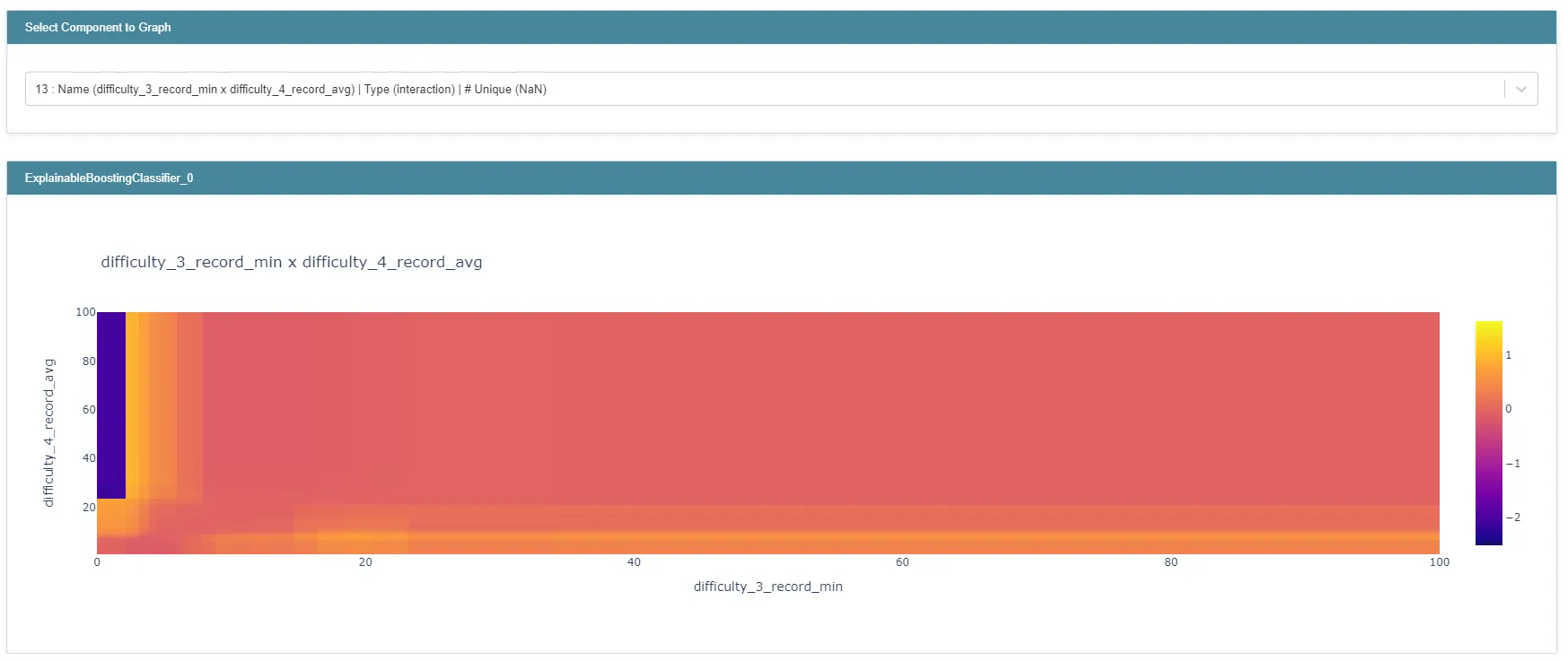
그림 13 : pairwise interaction term
상단 드롭다운 메뉴를 통해서 pairwise interaction term도 heatmap 형태로 살펴볼 수 있습니다. 위 heatmap은 난이도 3 트랙의 최고 기록과 난이도 4 트랙의 평균 기록의 interaction term의 출력값을 시각화한 것입니다.
이 heatmap을 통해서 알 수 있는 사실은:
1.
난이도 3 트랙 최고 기록이 좋지 않더라도, 난이도 4 트랙의 평균 기록이 좋다면 L2 라이센스 이상일 확률이 커진다고 모델은 판단하고 있습니다.
•
이 결과를 보고 이런저런 생각을 해볼 수 있습니다.
L2 라이센스 이상의 실력을 가진 유저가 주로 난이도 4인 트랙에서 게임 플레이를 하고 보통 좋은 성적을 얻고, 난이도가 3인 트랙도 한두 판 플레이한 경우가 있지 않을까? 하필 난이도가 3인 트랙에서 실수를 했거나, 열심히 하지 않은 경우도 있지 않을까? 이를 모델이 학습한 것은 아닌가? 등 질문을 해볼 수 있습니다.
중요한 아이디어라고 생각된다면 추가적인 EDA도 진행해 볼 수 있습니다.
2.
난이도 3 트랙의 최고 기록은 매우 좋지만 난이도 4 트랙의 평균 기록은 매우 좋지 않은 경우 해당 유저는 오히려 L2 라이센스 이상일 확률이 작아진다고 모델은 판단하고 있습니다.
•
난이도 3 트랙을 정상급으로 잘 주행하는 유저는 난이도 4 트랙도 잘 주행하지 않을까? 그렇다면 난이도 3 트랙의 최고 기록이 정상급이지만 난이도 4 트랙의 평균 기록은 상대적으로 떨어지는 유저들은 어떤 경우일까? 다른 사람들이 대신 한 판을 주행해 준 L3 라이센스 이하의 유저들이 있지 않을까? 이를 모델이 학습한 것은 아닌가? 등의 생각을 해볼 수 있고 EDA를 통해서 더 면밀한 검토를 해볼 수 있습니다.
이처럼 global explanation를 살펴보면 새로운 분석 주제가 떠오르는 경우도 있습니다.
다음으로는 local explanation을 살펴보겠습니다. 아래 코드를 실행하면 EBM 모델의 local explanation이 interactive 하게 표시됩니다. Dropdown 메뉴를 이용해서 EBM 모델이 특정 데이터의 추론을 어떻게 했는지 파악해 볼 수 있습니다.
local_explanation = ebm_model.explain_local(X_test[:10], y_test[:10])
show(local_explanation)
Python
복사
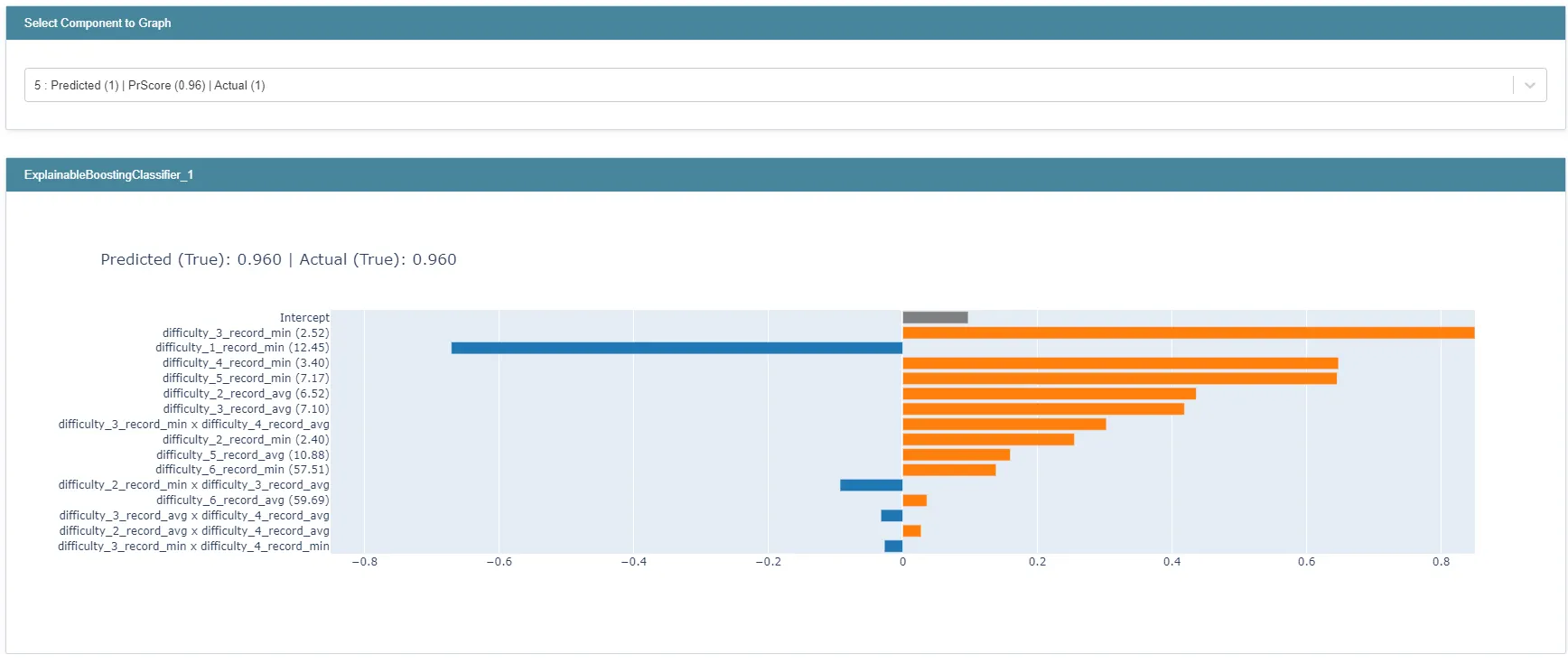
그림 14 : EBM의 결괏값 추론 히스토리 예시
위 그래프는 입력된 데이터의 6번째 obs/row를 EBM 모델이 어떻게 추론했는지 보여줍니다. 그래프는 해당 obs/row의 로짓값 계산에 가장 큰 절댓값 기여를 한 feature, interaction 15개의 값을 보여줍니다.
이처럼 local_explanation으로 EBM 모델이 어떤 이유에서 특정 추론 결과에 도달했는지 확인할 수 있습니다.
EBM을 활용한 모델 디버깅 사례
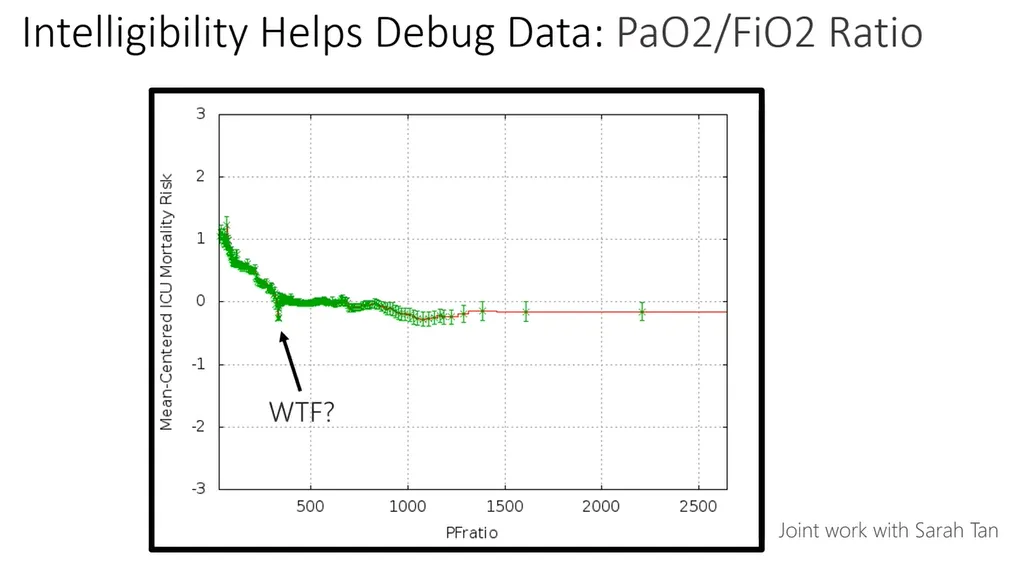
그림 15 : Intelligibility Helps Debug Data: PaO2/FiO2 Ratio
폐렴 환자 사망 예측 EBM 모델링 과정에서 feature function으로 모델 디버깅을 진행한 사례를 소개하고 글을 마무리하겠습니다.
폐렴 환자의 사망 예측에 사용된 feature 중 PFratio가 있습니다. PFratio는 흡입산소분율(FiO2)과 동맥혈산소분압(PaO2)의 비율을 의미합니다.
이 Feature 가 모델의 예측 결과에 어떤 영향을 미치는지 확인하고자 해당 feature function 그래프를 확인해 보았는데 이상한 점이 발견되었습니다. PFratio의 feature function을 살펴보면 EBM 모델은 PFratio가 낮을수록 사망 확률이 높아진다고 판단하다가 갑자기 PFratio가 300이 되면 사망 확률이 크게 낮아진다고 판단하는 것을 발견했습니다.
의학적으로 폐렴 환자들은 PFratio가 낮을수록 위급한 상태이기 때문에 이는 납득할 수 없는 결과입니다.
모델링을 담당한 분석가들은 이 현상의 원인을 밝히기 위해 모델 디버깅에 착수했습니다.
데이터 전처리 과정을 검토해 보니, 데이터셋의 PFratio 평균값이 300이었고. 데이터 결측치를 평균값으로 채웠다는 사실을 발견했습니다.
즉, 폐렴의 정도가 심하지 않아 병원에서 PFratio를 굳이 측정하지 않은 환자들의 PFratio가 300으로 채워졌습니다. 이를 EBM 모델이 학습해서 PFratio가 300일 때 환자의 사망 확률이 낮아진다고 예측하는 현상이 발생한 것입니다.
나가며
EBM은 높은 예측 성능과 설명 가능성을 모두 가지고 있는 훌륭한 모델입니다. 메모리 사용량이 많고 학습 속도가 느리다는 단점이 있지만 충분히 활용해 볼 가치가 있습니다.
Reference







 테크블로그 문의 gs_site_contents@nexon.co.kr
테크블로그 문의 gs_site_contents@nexon.co.kr