
Table of contents
들어가며

. . .
1. TabNet
1.1 소개 및 배경
TabNet은 2019년 발표와 함께 GCP의 built-in 알고리즘으로 적용된 정형 데이터에 특화된 딥러닝 모델입니다. 정형 데이터에서 DT(Decision tree)-based 모델과 DNNs(Deep neural networks)의 장점은 계승하고 단점은 제거하고자 했습니다. Sparse feature selection을 통해 핵심 feature에 집중하고 interpretability를 확보했습니다. 또한 다수의 정형 데이터셋에서 안정적으로 높은 성능을 보이는 것과 self-supervised learning으로 레이블이 모자란 데이터셋에서 성능을 크게 향상시킬 수 있음을 실험을 통해 증명했습니다[1].
DNN은 최근 몇 년 간 이미지, 자연어와 같은 비정형 데이터에 대해 비약적인 발전을 보여주었습니다. 이미지 분류의 대표적인 데이터셋인 ImageNet을 보더라도 2012년 AlexNet 등장 이후 2021년 Top5 Acc. 기준 84.6%에서 99.02%까지 상승했습니다[2][3].
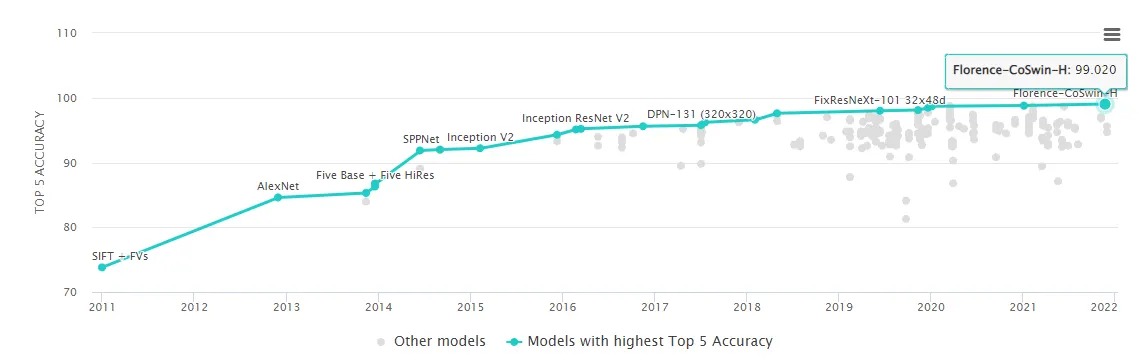
그림 1 : Image Classification on ImageNet(Top 5 Accuracy)[3]
왜 정형 데이터에서 DNN보다 DT-based 접근을 선호할까?
1.
초평면(hyperplane) 결정 경계를 가진 Decision manifolds에 대해 효율적입니다.
2.
모델 및 추론 결과에 대한 해석이 매우 용이합니다.
3.
학습 속도가 빠릅니다.
반면 DNN은 정형 데이터에 사용하기엔 파라미터가 지나치게 많고, 적합한 inductive bias(귀납 편향) 설계가 어려워 종종 최적해 탐색에 실패하기 때문에 기피되는 경향이 있습니다[1].
그러면 DNN의 장점은?
1.
정형 데이터와 함께 이미지와 같은 비정형 데이터를 효과적으로 인코딩할 수 있습니다.
2.
DT-based 모델과 마찬가지로 feature engineering 과정을 경감시킵니다.
3.
스트리밍 데이터로부터 학습할 수 있습니다.
4.
Domain adaptation, generative modeling, semi-supervised learning 같은 다양한 시도가 가능합니다.
TabNet은?
1.
전처리가 필요 없고 최적화에 경사하강법을 사용하는 구조로 end-to-end 학습에 유연하게 적용 가능합니다.
2.
Sequential attention을 사용하여 feature 선택의 이유를 추적할 수 있게하여 interpretability를 확보했습니다. 특히 기존 연구과 다르게 단일 모델로 instance-wise feature selection을 가능하게 합니다.
3.
다른 도메인의 회귀와 분류 데이터셋에서도 매우 높은 성능을 보이고, 두 종류(local, global)의 interpretability를 제공합니다.
4.
정형 데이터셋에서 처음으로 비정형 사전학습(unsupervised pre-training)이 성능을 크게 향상시킬 수 있음을 보였습니다.
1.2. TabNet에 주목한 이유
다음과 같은 현실적인 상황을 고민했습니다.
인텔리전스랩스에는 데이터가 정말 정말 많다.
데이터가 많습니다. 정확하게는 많고 다양합니다. 관측치도 상당히 많지만 차원수도 상당합니다. 데이터 타입도 정형, 비정형 데이터가 복합적으로 존재합니다.
•
대규모 데이터셋에서 높은 성능을 기대할 수 있어야 합니다.
•
비정형 데이터와 유기적으로 결합할 수 있어야 합니다.
데이터는 완벽하지 않다.
보통 현실에서 맞닥뜨리는 데이터는 완벽하지 않습니다. 유명한 공개 데이터셋조차 결측치(missing values)나 잘못된 레이블(noisy labels)이 포함되어 있는 경우가 많습니다. 현실적으로 시간이 한정된 상태에서 안 그래도 많은 데이터에 모든 부분을 세세하게 통제하기는 쉽지 않습니다.
•
입력 데이터에 결측치가 있어도 일반화(generalization)에 강하면 좋습니다.
•
잘못된 레이블에 의한 성능 하락을 최소화할 수 있어야합니다.
실제 서비스에 적용해야 한다.
오직 높은 벤치마크 결과에만 집중하긴 어렵습니다. 실제 서비스에 적용해야 하는 만큼 벤치마크만 좋은 모델보다는 운영 및 유지 보수가 용이해야 합니다. 특히 데이터 갱신주기가 짧고 실시간 서비스를 지향한다면 학습/추론 속도도 신경 써야 합니다.
•
실시간 서비스라면 모델이 너무 무겁지 않고, 학습 및 추론 속도가 빨라야 합니다.
•
스트리밍 데이터에 대응할 수 있어야 합니다.
바라는 게 많지만 어쨌든 다 된다고 합니다.
앞서 TabNet의 특징에서 말씀드렸듯 TabNet은 마치 고민했던 내용들을 전부 해결할 수 있으면서도 성능까지 매우 뛰어난 것처럼 보입니다. 실제로는 어떤지 좀 더 자세히 살펴보겠습니다.
2. TabNet
2.1. 개요
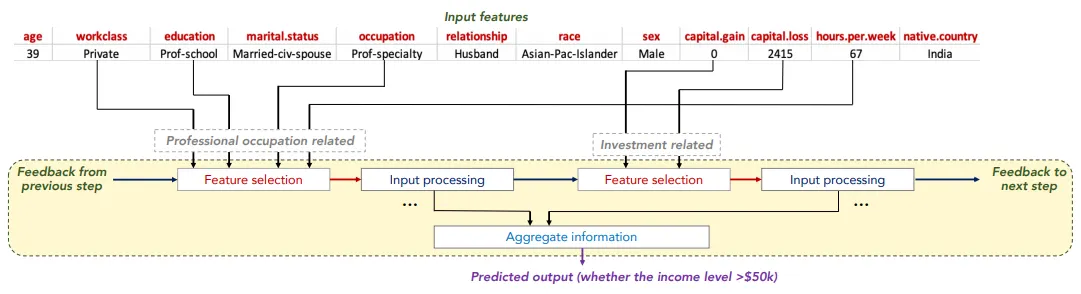
그림 2 : TabNet의 Sparse feature selection 예시(Adult Census Income prediction)[1]
TabNet은 Sparse feature selection을 제안해 학습 효율을 높이고 interpretability를 확보했습니다. feature selection mask를 학습이 가능하도록 변수로 지정하고, sparse selection이 가능하도록 활성함수로 sparsemax[6]를 사용했습니다. Sparsemax는 softmax와 다르게 출력값에 0, 1이 포함되므로 지나치게 중요성이 낮은 feature에 대한 learning capacity 낭비를 방지합니다.
[그림 2]에서 나타나듯이 여러 단계(step)의 decision step을 거치면서 각 단계마다 feature selection mask를 구할 수 있습니다. 그래서 단계 별로 핵심 feature를 파악할 수도 있고, 단계 별 mask를 합하면 개별 입력 데이터에 대해서도 feature의 중요도를 파악할 수 있습니다. 이를 통해 instance-wise feature selection을 달성하고 local interpretability를 확보합니다. 당연히 각 mask를 전체 데이터에 대해 합하여 살펴볼 수도 있습니다(global interpretability).

그림 3 : TabNet encoder architecture[1]
전체적인 TabNet 인코더의 구조입니다. 간략하게 말씀드리면 Feature transformer에서 인코딩을 수행하고 Attentive transformer가 인코딩 결과로 feature selection에 해당하는 마스크를 생성합니다. 이 과정을 여러 단계의 decision step을 거치면서 반복하고, 이전 단계의 feature는 다음 단계의 마스크를 생성하는데 활용됩니다. 자세한 내용은 후술하겠습니다.
2.2. Feature Selection(Attentive transformer)

그림 4 : Attentive transformer[1]
Attentive transformer는 학습 가능한 마스크(learnable mask)를 생성합니다. 이 마스크는 핵심 feature에 대해 soft selection을 수행합니다.
•
◦
◦
또한 softmax 대신 sparsemax를 활성함수로 사용하여 각 decision step마다 중요도가 떨어지는 feature에 learning capacity가 낭비되지 않도록 했습니다. 그리고 prior scale term()을 통해 이전 decision step의 feature 재선택 비율을 조절합니다.
앞서 설명드린 과정이 포함된 마스크 의 전체 수식은 아래와 같습니다.
•
◦
◦
◦
◦
마스크는 sparsemax를 활성함수로 사용하므로 마스크 벡터의 총 합은 1입니다( ). 이를 통해 일반적인 분류 모델에서 softmax로 각 클래스로 예측될 확률을 짐작하듯 feature의 중요도를 파악할 수 있게 됩니다. 는 FC, BN layer로 구성되어 있습니다.
Prior scale term()으로 영향력이 지나치게 큰 feature가 여러 decision step에서 지나치게 중복 선택될 가능성을 조절할 수도 있습니다.
수식은 아래와 같습니다.
•
◦
Relaxation parameter( )을 통해 재선택 가능성을 조절합니다. 일 때, feature는 오직 1번의 decision step에서만 선택되도록 강제되며 가 증가함에 따라 여러 결정 단계에서 선택될 수 있도록 조정됩니다. 첫 번째 decision step(step=0)에서는 로 초기화됩니다. 만약 self-supervised learning을 사용하는 경우 결측값을 포함한다면 0으로 초기화됩니다.
마지막으로 선택된 features의 sparsity 조절을 위해 다음과 같은 entropy form을 제안합니다.
•
은 안정성을 위한 상수입니다. 이러한 Sparsity regularization은 features가 중복되는 데이터셋에 inductive bias를 제공합니다.
2.3. Feature Processing(Feature transformer)
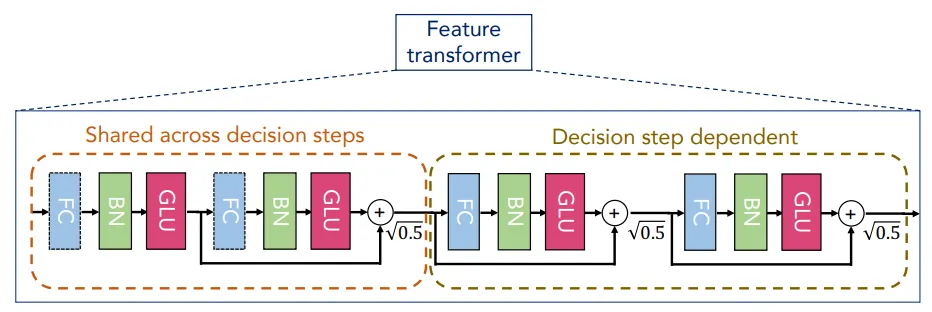
그림 5 : Feature transformer[1]
마스크에 의해 선택된 feature는 마스크에 feature vector를 곱한 로 표현됩니다. 그리고 feature transformer decision step은 아래와 같습니다.
•
◦
◦
는 의 decision step, 는 의 attentive transformer 입니다.
저자들은 feature transformer의 구조를 위 그림과 같이 4개의 블럭으로 구성된 예시로 설명하는데, 효율적이고 강건한 학습을 위해 다음과 같은 특징을 가졌습니다.
1.
앞선 2개 블럭은 전체 decision step에서 가중치를 공유(shared weights)합니다.
2.
각 블럭은 활성함수로 GLU를 적용하고, 로 정규화(normalization)된 skip connection을 적용했습니다.
3.
최종적으로 overall decision embedding 과 예측값 은 다음과 같습니다.
•
•
◦
2.4. Interpretability

그림 6 : Feature importance masks and the aggregate feature importance mask example on Syn2 and Syn4[1][8]
위 그림은 각 decision step의 마스크 와 각 마스크가 합쳐져(aggregated) 샘플의 feature importance로 해석 가능한 의 시각화입니다.
자세히 설명드리면 이 0에 해당하는 feature는 결정에 아무런 영향을 주지 않았다고 해석할 수 있습니다. 만약 이라면 배치의 feature는 영향력이 없다는 의미입니다. 또한 앞선 수식에서 가 linear function이면 계수는 곧 feature importance로 볼 수 있습니다. 비록 각 decision step은 비선형적이지만 최종적으로는 선형함수를 통해 조합되어 이 같은 해석이 가능해집니다.
이 과정을 각 decision step마다 반복하면 각 step 별로 위 그림과 같은 결과를 얻을 수 있습니다. 각 step에서 음수 값은 결정계수=0으로 처리하기 위해 를 사용했습니다. 수식으로 표현하면 아래와 같습니다.
•
직관적으로 알 수 있듯 이면 마스크에서 선택()되더라도 feature importance를 0으로 만듭니다. 의 값이 커진다면 aggregation 단계의 overall linear combination에서 더 높은 feature importance를 가질 가능성이 높아집니다.
지금까지 설명드렸듯 feature selection과 이에 대한 feature importance는 instance-wise입니다. 기존 시도[8][9]들과는 다르게 1개의 모델, end-to-end 구조로 이를 달성했습니다.
또한 각 샘플에 대한 feature importance는 local interpretability에 해당하지만 이를 모든 샘플에 대해 통합(aggregation) 한다면 전체 데이터셋에 대해서도 해석 가능(global interpretable)합니다.
2.5. Self-supervised Learning

그림 7 : Self-supervised tabular learning example[1]
TabNet에서는 레이블이 없거나 결측치가 포함된 데이터셋에서 유용하게 사용할 수 있고, pre-training에도 사용할 수 있는 self-supervised learning을 제안합니다. Encoder의 출력값을 입력받아 feature를 복원(reconstruct)하는 Decoder를 연결한 Autoencoder 구조입니다.
Decoder는 각 step마다 feature transformer에 FC layer가 연결된 구조입니다. 각 step FC layer 출력값의 aggregation 값이 입력 features를 복원합니다.
좀 더 자세히 말씀드리면 다음과 같습니다.
1.
를 만족하는 binary mask를 생성합니다.
2.
로 encoder 입력값()을 마스킹합니다.
•
3.
Decoder의 출력은 를 복원합니다.
4.
로 초기화하여 encoder는 알려진 feature에 집중하도록 합니다.
2.6. Experiments

그림 8 : Test AUC[1]
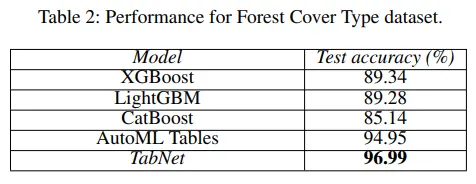
그림 9 : Performance for Forest Cover Type dataset[1]
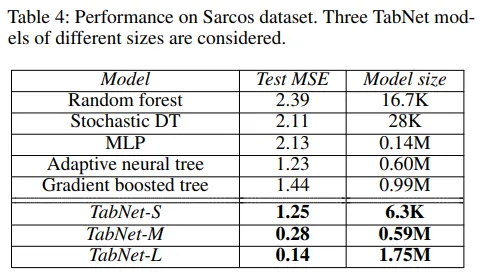
그림 10 : Performance on Sacros dataset[1]
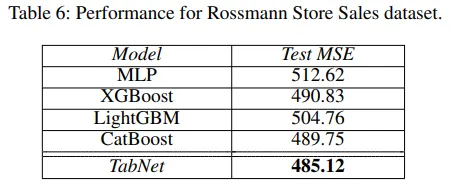
그림 11 : Performance for Rossmaann Store Sales dataset[1]
실험 결과를 보면 TabNet은 여러 데이터셋에서 가벼우면서도 최고 성능을 보이고 있습니다.
Table 1의 feature selection 모델과의 비교를 보시면 INVASE와 비교되는데, INVASE는 2개의 모델로 구성된 actor-critic 모델이고 파라미터 크기는 101k입니다. 반면 TabNet은 1개의 단일 모델로 구성되었으며 파라미터 크기는 Syn1-Syn3에서 26k, Syn4-Syn6에서 31k입니다. 심지어 Poker Hand induction 데이터셋에서는 룰을 거의 완벽하게 학습(99.2%)합니다.
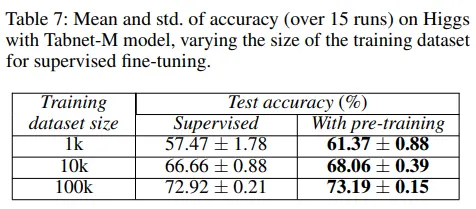
그림 12 : self-supervised learning 결과[1]
Self-supervised learning도 매우 높은 성능 향상 효과가 있었습니다. Table 7과 Figure 7을 보시면 성능뿐만 아니라 수렴 속도도 상당히 가속되는 걸 알 수 있습니다.
3. 더 살펴보기
3.1. 사용사례
원문에 따르면 TabNet은 여러 가지 편의성과 뛰어난 성능을 보입니다. 그렇다면 TabNet이 실제로 사용된 사례가 있을까요? 실제 환경에서는 어떨까요? 캐글 대회와 인텔리전스랩스의 사례를 간단하게 살펴보겠습니다.
Mechanisms of Action Prediction(Kaggle, 2020)
캐글에서 2020년 있었던 대회인 MoA(Mechanisms of Action Prediction)[11] 우승팀이 TabNet을 사용했습니다. 대회나 우승 솔루션에 대한 자세한 내용보다는 성능과 결과 위주로 소개 드리겠습니다.
MoA의 목표는 생물학적 활동에 따른 약물 분류이며 multi-label classification 문제입니다. 대략적인 데이터셋의 명세는 아래와 같습니다.
•
Training dataset
◦
n_rows = 23,814
◦
n_cols = 876
◦
y_cols = 207
관측치의 규모보다는 feature space와 target space가 상당히 크고, target space의 sparsity가 높은 특징을 가졌습니다.

그림 13 : 우승팀 솔루션 다이어그램[13]
다만 TabNet을 사용한 모델이 저자들이 주장한 만큼 압도적인 성능을 보여주진 못합니다.
아래 표를 보시면 Public LB, Private LB에서 중간 이하의 결과를 보입니다.
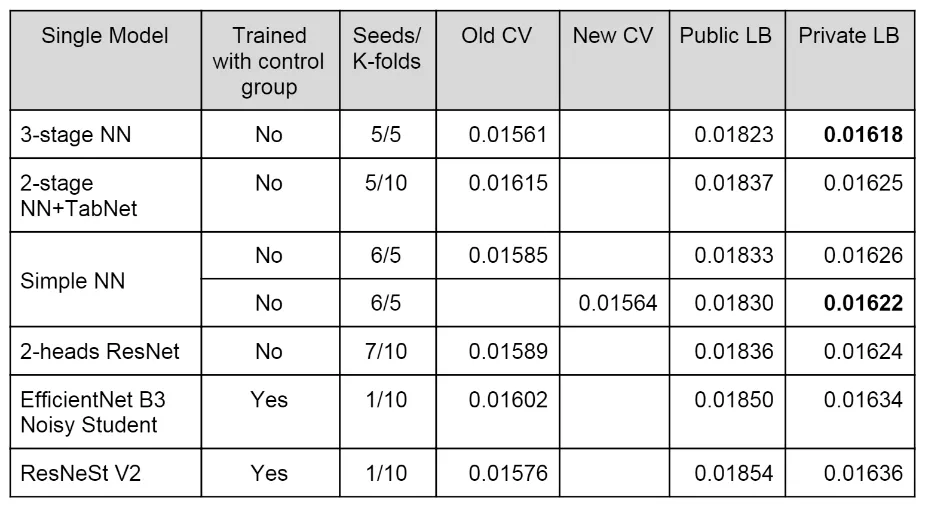
그림 14 : Winnig Blend with 7 Models[13]
추가로 살펴볼 만한 언급도 있습니다. 아래의 TabNet이 사용된 모델의 전체 구조를 보시면 Stage 2에서 TabNet이 사용되고 Stage 1은 TabNet이 아닌 다른 NN이 사용되었습니다. 이에 대해 저자들은 TabNet이 non-scored predictions 부분에서 좋은 결과를 내지 못해 제외했다고 언급합니다[13].
TabNet is only used for the 2nd stage instead of the first one, because it was not producing good results on non-scored targets[13].

그림 15 : TabNet 사용 모델 구조[13]
부정거래 식별(인텔리전스랩스)
인텔리전스랩스에서는 유저의 부정거래 식별에 TabNet을 사용했습니다. Metrics는 자세한 스코어가 아닌 F1-score 순위값으로 대체했으며, 세세하게 설명드리지 못하는 점 양해 부탁드립니다.
우선 성능 결과부터 살펴보겠습니다.
Model | Rank(F1-score) |
LGBM(v2) | 1 |
LGBM(v1) | 2 |
TabNet(v3) | 3 |
TabNet(v2) | 4 |
CNN(v2) | 5 |
TabNet(v1) | 6 |
CNN(v1) | 7 |
기대와는 다르게 LGBM보다 성능이 떨어지는 것으로 보입니다. 하지만 다음 사항을 고려하여 성능이 조금 부족하더라도 TabNet을 메인 모델로 선택했습니다.
고려한 내용은 다음과 같습니다.
•
모델이 가볍고 학습 및 추론 속도가 빠릅니다.
•
다른 비정형 데이터 인코더와 연결되는 end-to-end 구조가 필요했습니다.
•
별도의 알고리즘 없이 instance-wise feature selection이 가능합니다.
특히 instance-wise feature selection에서 만족스러운 결과를 보여주었습니다. 아래는 GradCAM[14]으로 CNN(v2)의 예측에 기여가 높은(이후 feature importance로 설명) 노드를 시각화한 자료입니다. 그림의 세로축은 features, 가로축은 거래의 sequence입니다. 셀의 색상이 밝을수록 높은 중요도를 갖고 있다고 볼 수 있는데 생각보다 TP, TN, FP, FN에서 시각적으로 별다른 차이가 관찰되지 않았습니다. 원인은 기여도가 높은 feature가 각 sequence마다 반복적으로 선택되었기 때문으로 추정됩니다.
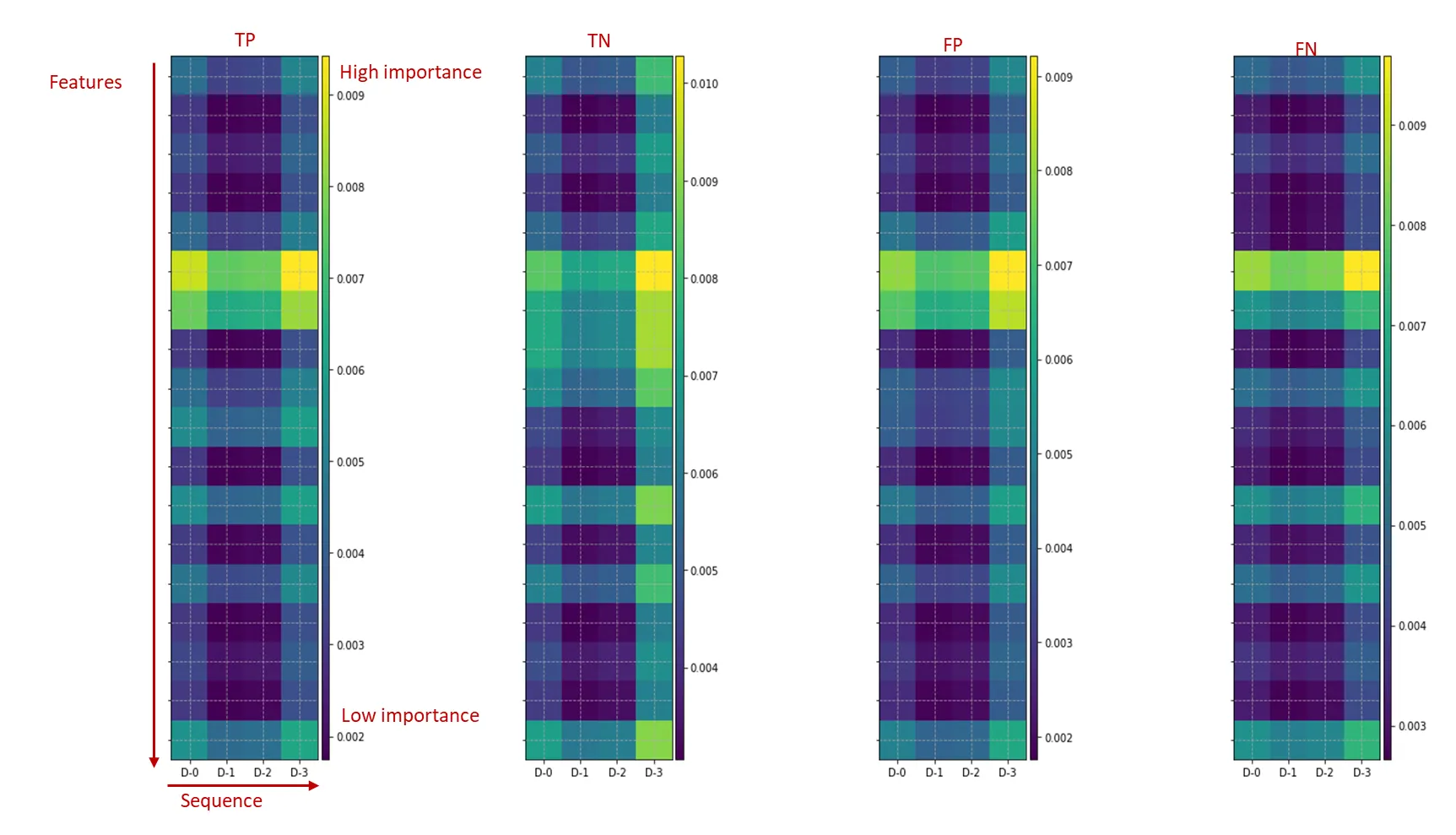
반면 TabNet은 예측 종류별 feature selection에서 시각적인 차이를 확인할 수 있었습니다. 또한 정성분석에서도 납득할 만한 결과를 보여주었습니다.

그림 17 : 예측종류별 TabNet feature importance 시각화
3.2. 과연 TabNet으로 충분할까?
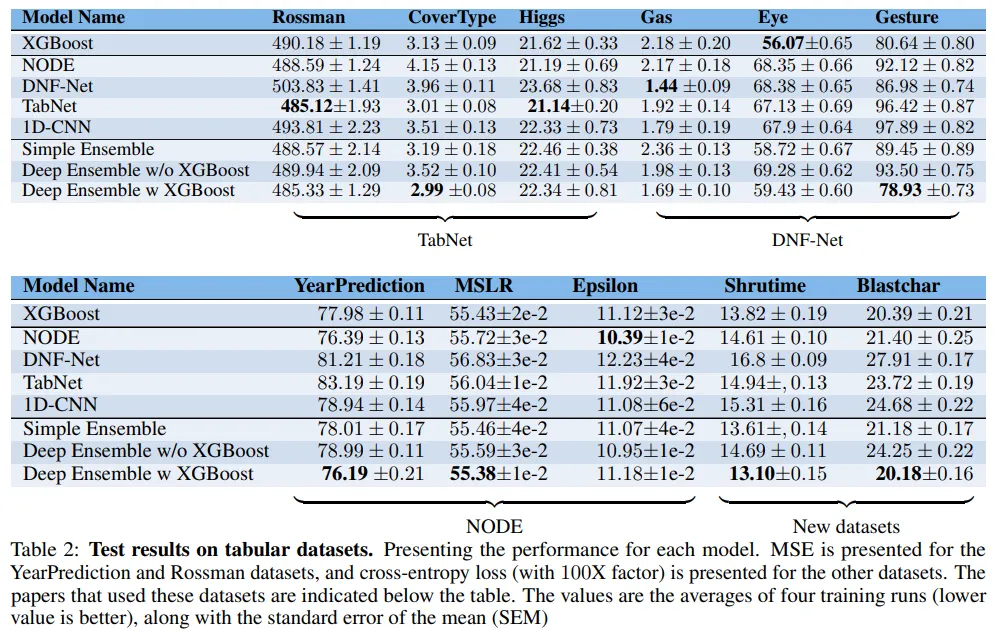
그림 18 : Test results on tabular datasets[10]
결과가 참 흥미롭습니다. 어떤 딥러닝 모델도 다른 것들보다 일관적으로 나은 성능을 보여주지 못합니다. 딥러닝 모델과 XGBoost의 앙상블 모델만이 대부분의 경우에서 나은 성능을 보여주고 있습니다. 측정된 성능들은 신뢰성 확보를 위해 통계적 검정을 거쳤으며, 로 우연에 의해 순위가 잘못되었을 가능성은 극히 희박합니다[10].
3.3. 정형 데이터에 딥러닝을 쓸 필요는 없는걸까?
“Tabular Data: Deep Learning is Not All You Need”의 저자들은 TabNet의 실험 결과에 정면으로 의문을 제기했습니다. 특정 딥러닝 모델이 나은 성능을 보이는 것은 오직 해당 딥러닝 모델의 실험 결과에서만 그렇다고도 했습니다.

그림 19 : Average relative performance deterioration[10]
하지만 그렇다고 해서 저자들이 정형 데이터에서 TabNet이나 딥러닝을 사용하는 게 잘못되었다고 말하진 않습니다. 다음의 이유로 비용 제약이 크다면 XGBoost를 주로 사용하거나 아니면 딥러닝 모델을 XGBoost와 앙상블하여 사용하길 추천합니다.
1.
2.
하지만 딥러닝 모델은 최적화 난이도가 높고 오래 걸립니다.
3.
성능 및 속도, 비용, 시간 등 현실적인 상황을 고려해야 합니다.
이렇게 정형 데이터에는 딥러닝을 앙상블에만 사용하는 게 나을까요? 기본적으로 DT-based 모델을 사용하는 게 나은 선택일까요? 원론적이지만 개인적으로는 현실적인 상황에 맞게 고려하는 게 중요하다고 생각합니다. 딥러닝이 무용하다고 보기엔 MoA winning solution[12]의 모델들도 전부 DNN 모델입니다. 또한 TabNet도 원 저자들이 제시한 만큼의 압도적인 성능인지가 의문일 뿐, MoA의 사례[11]를 보면 딥러닝 모델들이 좋은 선택인 경우도 있어 보이며, 인텔리전스랩스의 사례에서도 성능 외 다른 장점도 존재합니다. 결론적으로는 성능을 이유로 딥러닝 모델이나 TabNet을 사용하기보다는 현실적인 상황을 고려하여 딥러닝의 장점이 필요할 때 TabNet같은 딥러닝 모델을 사용하는 게 어떨까 합니다.
. . .
나가며

1. 입력 데이터에 대한 전처리 없이 학습 가능합니다.
2. 단일 모델의 end-to-end 구조로 instance-wise feature selection을 수행하며 다른 타입의 데이터와 유연하게 연결 가능합니다.
3. Semi-supervised learning, Domain adaptation 등 다양한 애플리케이션 시나리오에 적용 가능합니다.
4. 정형 데이터에 대해 처음으로 unsupervised pre-training을 사용하여 높은 성능 향상을 보였습니다.
하지만 원 저자들이 제시한 만큼 일관적으로 뛰어난 성능을 보이는지는 고민이 필요하며, 딥러닝 모델을 단독으로 사용하기보단 XGBoost와 앙상블 모델을 구성하길 추천하는 시각도 있습니다[10].
결론적으로는 벤치마크 성능만을 이유로 TabNet이나 딥러닝 모델을 사용하는 건 바람직한 선택은 아닌 것 같습니다. 딥러닝이 갖는 장점을 활용하거나 DT-based 모델과 앙상블을 위해 선택을 고려하는 것이 좋다고 생각합니다.

